
A plenary lecture delivered at Collective Imagination 2019 (the TMS users’ conference), Dublin, 10 April 2019.
Abstract
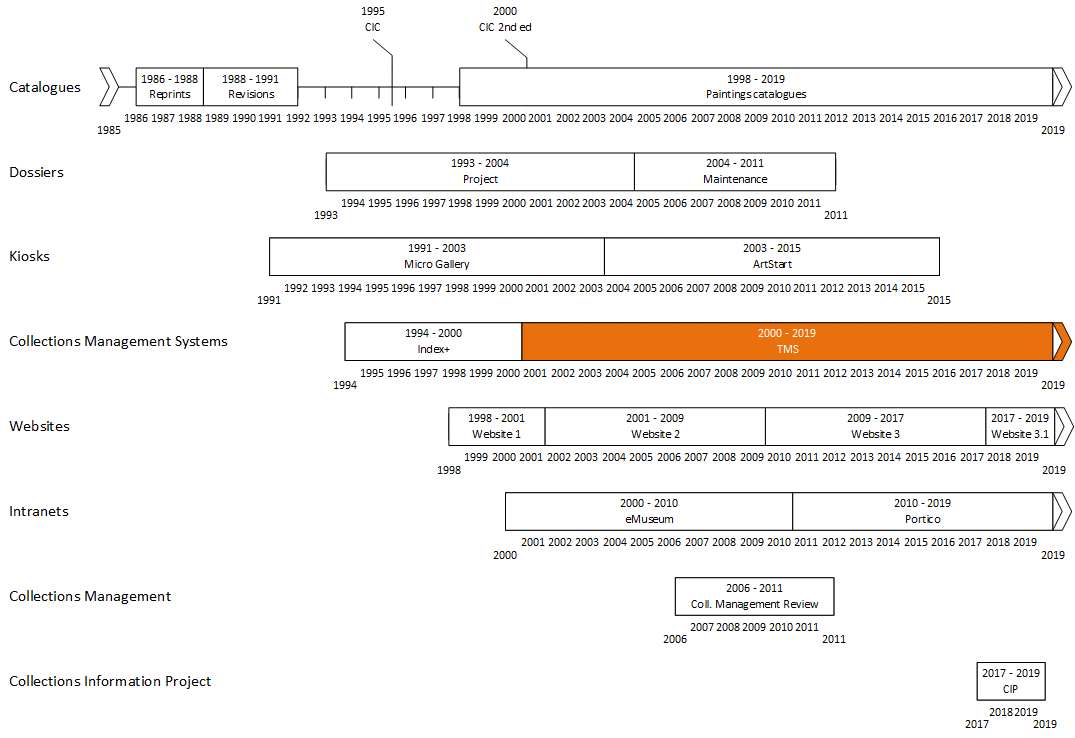
In 1990, The National Gallery’s on-site, self-contained Micro Gallery was at the cutting edge of the digital presentation of collections. In 2000, we became the first UK museum to adopt TMS, since when we’ve used the system to manage our collections, but not to catalogue them – we still use printed books. In 2019, with a recently-appointed director, we wish to publish rich, deep, digital information about our collections. I will talk about how we’ve used TMS to manage our collections, catalogue them, and present them to our audiences in the past; what we’re doing now; and our plans for the future.
Introduction
First of all, I must thank Jon Thristan, Jay Hofmann and Gallery Systems for the invitation to speak to you today. I’m only too aware as I do so that I am a comparative newcomer to TMS, and that most of you have been using the system for far longer than I have, and are much more experienced and skilled at doing so.
I stand here today on the shoulders of giants: many of you will know my predecessor as the National Gallery‘s Collection Information Manager, Gillian Essam, and her former colleague, Tim Henbrey – who also worked for a while for Gallery Systems. Both spoke to this very conference in 2011, and both have generously provided much of the information that I will be sharing with you today.
The time available to me means that I will focus on just a few key aspects of digital collection information at the National Gallery: kiosks, websites, analogue and digital cataloguing, collections management – and data integration. I’ll therefore ignore a range of external and internal projects, and systems managing and presenting collection information. I should also warn you that the historical information I’m presenting is very much a work in progress – it largely draws on personal recollection and conversations with various key players: I still have to go digging in the Gallery’s official records.
Cataloguing before TMS
Schools catalogues

I would like to start with our analogue collection information. Our story begins in the Second World War, when the Gallery’s paintings were evacuated from London to a slate quarry in Manod, in north Wales.

Here, they were kept in relatively stable conditions and, free from distractions, the Gallery’s staff – notably Martin Davies, the man on the right in the slide – could give their undivided attention to the paintings.

The result was a series of catalogues, arranged by school of painting, the first of which was published immediately after the War in 1945, which set a new standard in the detail and thoroughness of their assessments and descriptions.

Work on the ‘schools catalogues’, as they were known, continued until 1971, and they eventually extended across the Gallery’s entire collection.
The Illustrated General Catalogue and Complete Illustrated Catalogue
We also published two summary catalogues of the whole collection, the Illustrated General Catalogue in 1973, and the Complete Illustrated Catalogue (known as the CIC) in 1995. These gave the basic tombstone information for each painting, a very brief descriptive note, and a small image. The CIC added a summary provenance and bibliography.

Paintings catalogues
In the early 1990s, we decided that the schools catalogues were in need of a complete overhaul, and began work on a new series. The first of these, Judy Egerton’s catalogue of the British School, was published in 1998. With their large formats, lavish full-colour illustrations, extensive discussions, and detailed scientific and technical information, this new series of ‘paintings catalogues’ again marked a significant step forwards in the publication of catalogue information about museum objects. So far, nine paintings catalogues have been published, with another two either in the press or at an advanced stage of preparation.

But it’s worth noting that for many paintings, the original schools catalogue still provides the most current published extensive Gallery catalogue entry.
Dossiers
Whilst work was under way on the CIC and the first of the paintings catalogues, in about 1993 we began a major project to organise and improve our dossiers – what other museums would call ‘history’ or ‘object’ files – so that they could become a single source for as much information as possible about a painting, supporting our research and cataloguing work, and engagement activities such as talks and lectures.
The work involved was immense and, for each painting, involved:
- Drawing up a full bibliography and exhibition and loan history
- Listing references to the painting in the Gallery’s archive, and transcribing key documents
- Listing photographs of the painting in the dossier
- Listing other written material in the dossier – correspondence and so on
- Listing related works – copies, versions, etc.
- Photocopying the current catalogue entry and any other significant catalogue entries and articles
- Rehousing everything to archival standards

By the early 2000s, only about half the paintings had been finished, and the Gallery decided to continue at a lower level; the project was eventually completed in 2004. Work continued keeping the dossiers up-to-date until 2011.
When work began, the Gallery had no collection database, so all the dossier information was assembled as a series of word processor files – initially in WordPerfect, but soon transferred to Microsoft Word.

The various catalogues and the dossiers are our raw materials.
Data presentation before TMS
The Micro Gallery

The story of our digital presentation of the collection begins nearly 30 years ago, in 1991, when I had just graduated, and was indexing journals in the National Gallery’s Library. That year, the Queen opened a major extension to the Gallery, the Sainsbury Wing.

As well as the 16 galleries in the new wing, purpose-built for the display of our collection of fourteenth and fifteenth-century paintings, there was a long thin room on the first floor: the Micro Gallery.


Developed by Cognitive Applications, the Micro Gallery comprised a dozen full-colour touch-screen terminals, each of which presented the Gallery’s entire collection, and the more important long loans in, with a large image – mostly in colour – and at least a page of information for each painting.
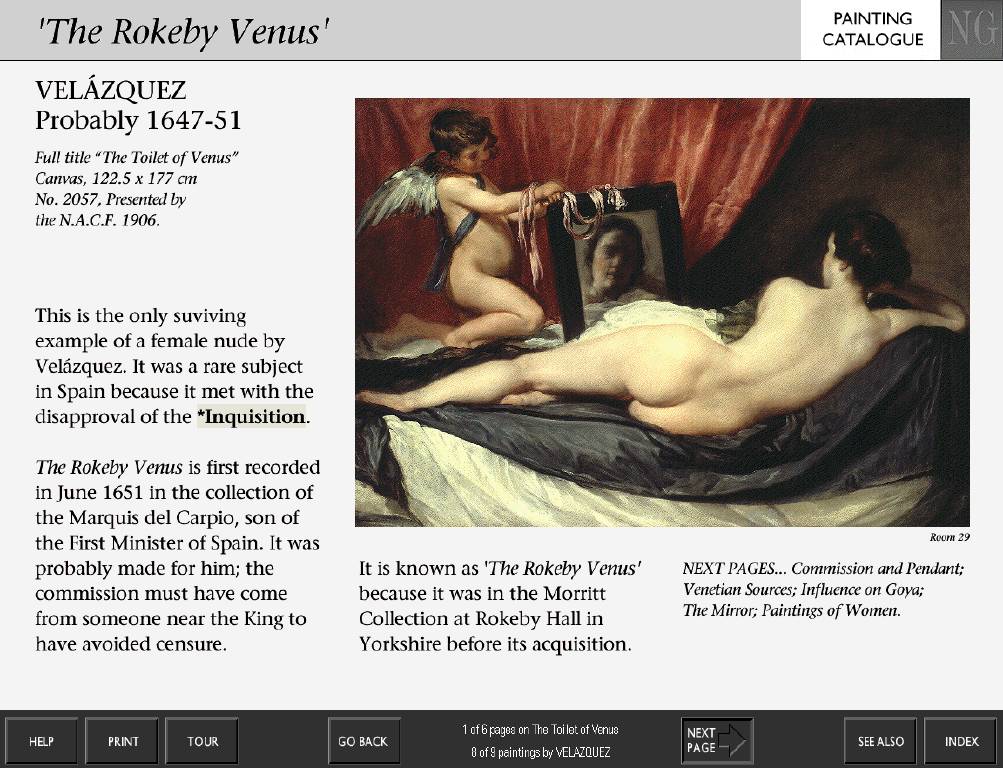
The system was explicitly designed, in the words of the Gallery’s press release, to make ‘no assumptions about knowledge of art or computers and strike… a careful balance between being entertaining and educational.’1
Users could browse their way into the collection by four different routes:
- An alphabetical list of Artists, leading to a page of biography and thumbnail links to paintings by the artist
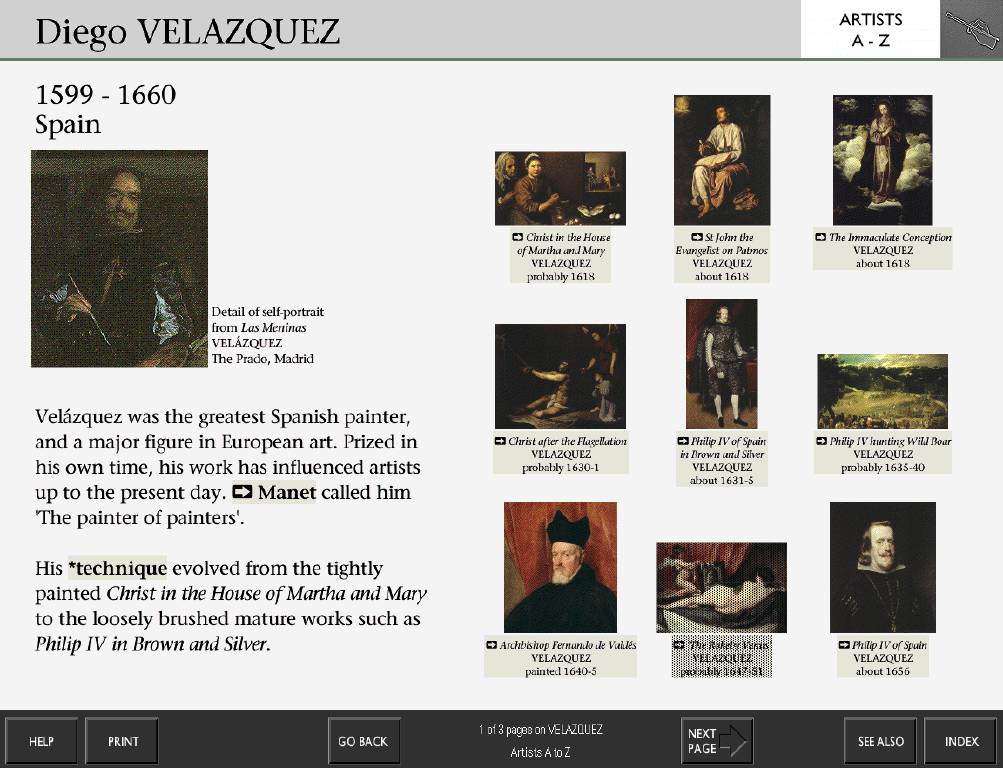
The Artist screen from the National Gallery’s Micro Gallery collection information kiosk. Photo: © The National Gallery London. Courtesy of Cogapp. - Picture Types, based on genres, such as altarpiece, still-life, landscape, or portrait
- An Historical Atlas, with a map that led to a series of entries for individual artistic centres, broken down into twenty-five or fifty-year periods
- And a General Reference section, which broadly listed paintings by subject
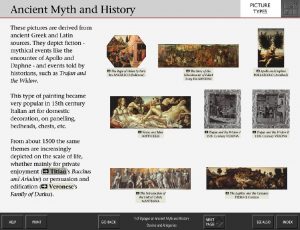
A Subject screen from the National Gallery’s Micro Gallery collection information kiosk. Photo: © The National Gallery London. Courtesy of Cogapp.

From a painting’s entry, users could browse to the relevant entry or entries in each of these four areas, and so see other, related paintings.

Further information was provided by cross-reference links within the text, and pop-up glossary entries. The more important paintings were given many pages of content, and there were fifty-two animations explaining particular aspects of certain paintings. Users could print out pages from the system, or a plan of the Gallery with a customised tour of the paintings they had viewed.
The Micro Gallery was written from scratch using Apple’s HyperCard 2.0 and THINK C. The kiosks were connected to a central control computer, but the system was otherwise completely standalone – it had no external data source.
This was a huge achievement, and in one fell swoop placed the National Gallery at the cutting edge of the digital presentation of information about its museum collections. The same system went on to be used by the San Diego Museum of Art in 1994, and the National Gallery of Art in Washington DC [3.25 MB PDF] in 1995.
In fact, the Micro Gallery became a source of digital collection information. The researchers who had worked on it were retained to develop their content into the CIC, using a version of the Micro Gallery editorial software to produce print-ready QuarkXPress page layouts.
Website
All this happened as the Web was in its infancy: the first web browser was made publicly available two months after the Micro Gallery was launched.2

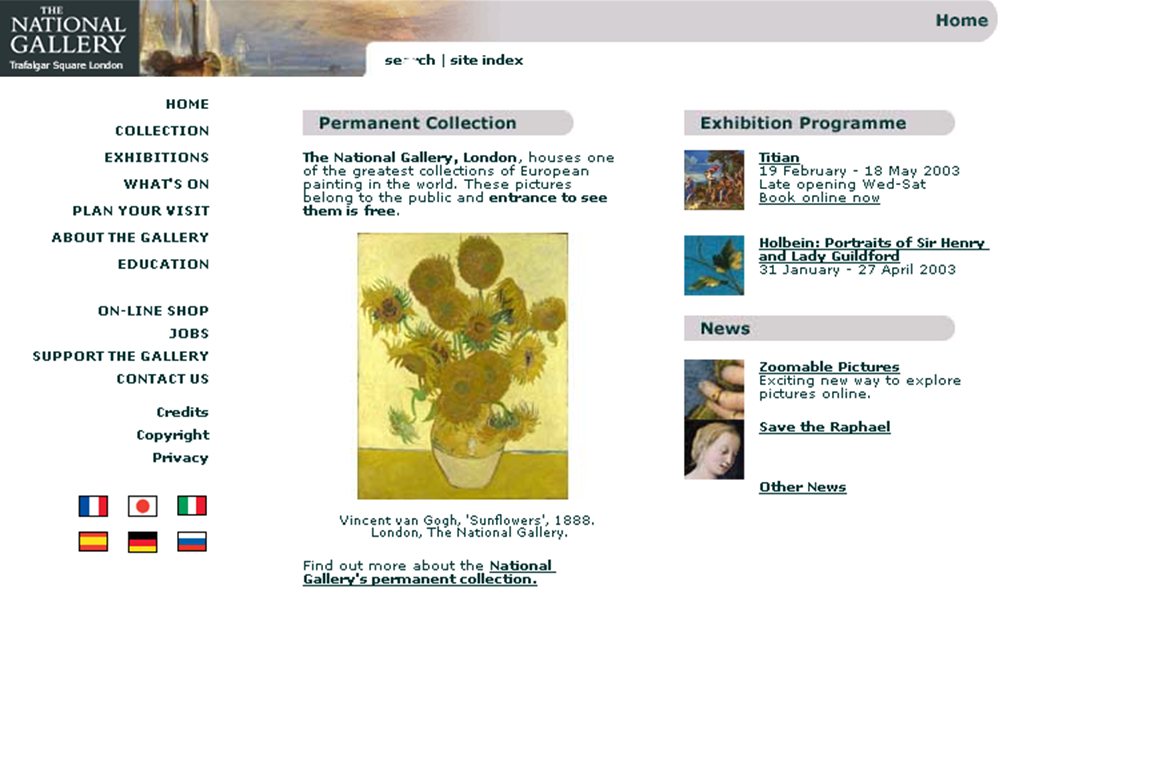
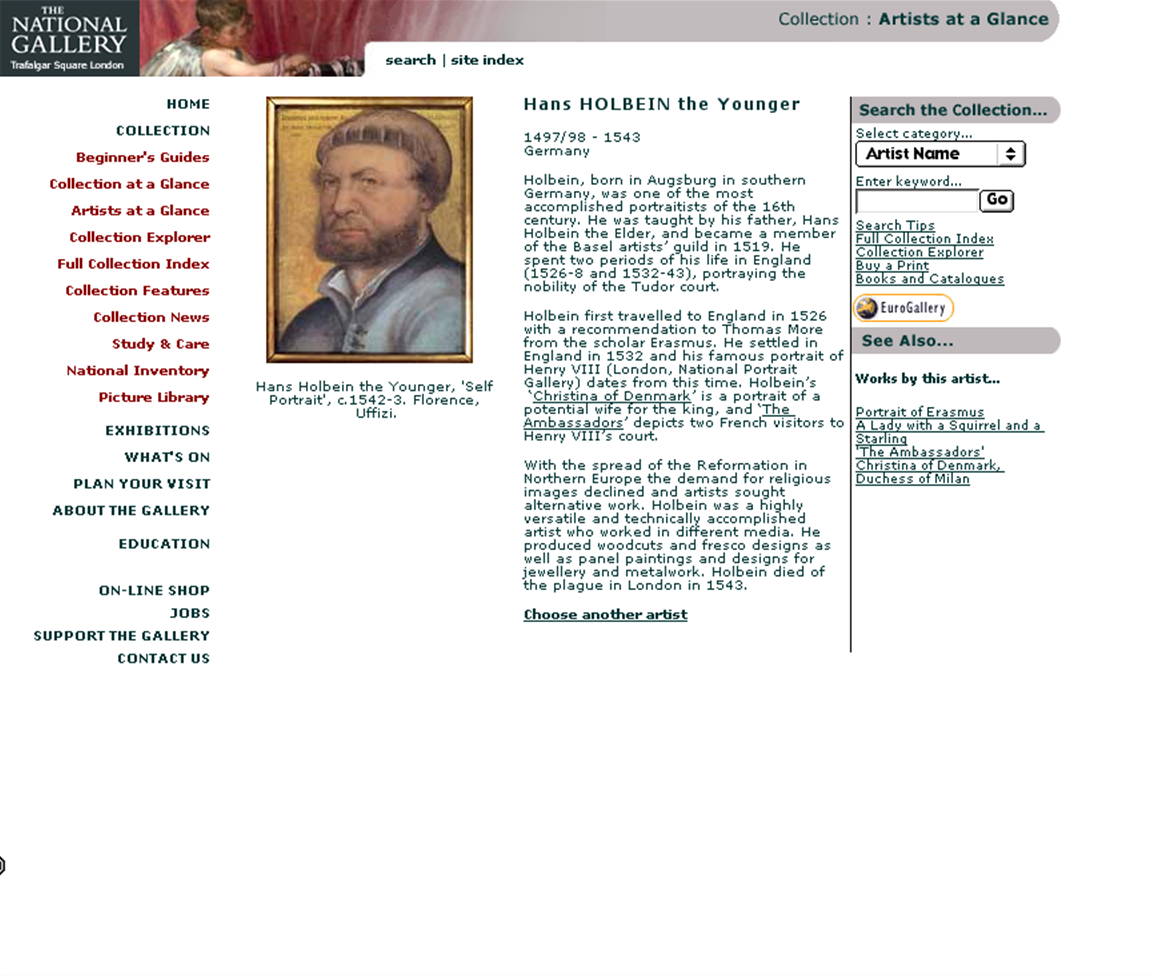
The Gallery’s first website seems to have gone live in 1998. It was effectively a placeholder, with only a few static pages holding information about 20 or so of our highlight paintings.
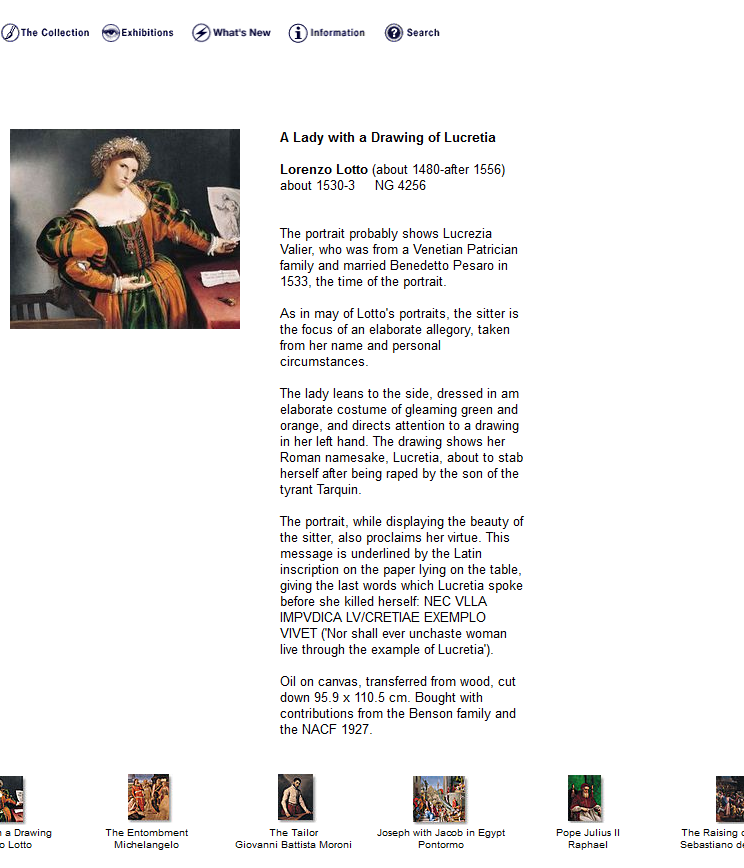
In 2000, our New Media Department started a major project to completely overhaul the website, and in a little over a year, a small team of three editors used whatever texts were available – in many cases drawing upon the Micro Gallery and the Complete Illustrated Catalogue – to produce content for our entire collection, with some help from curators.
A programme of new photography meant that all paintings were finally reproduced in high-resolution colour.
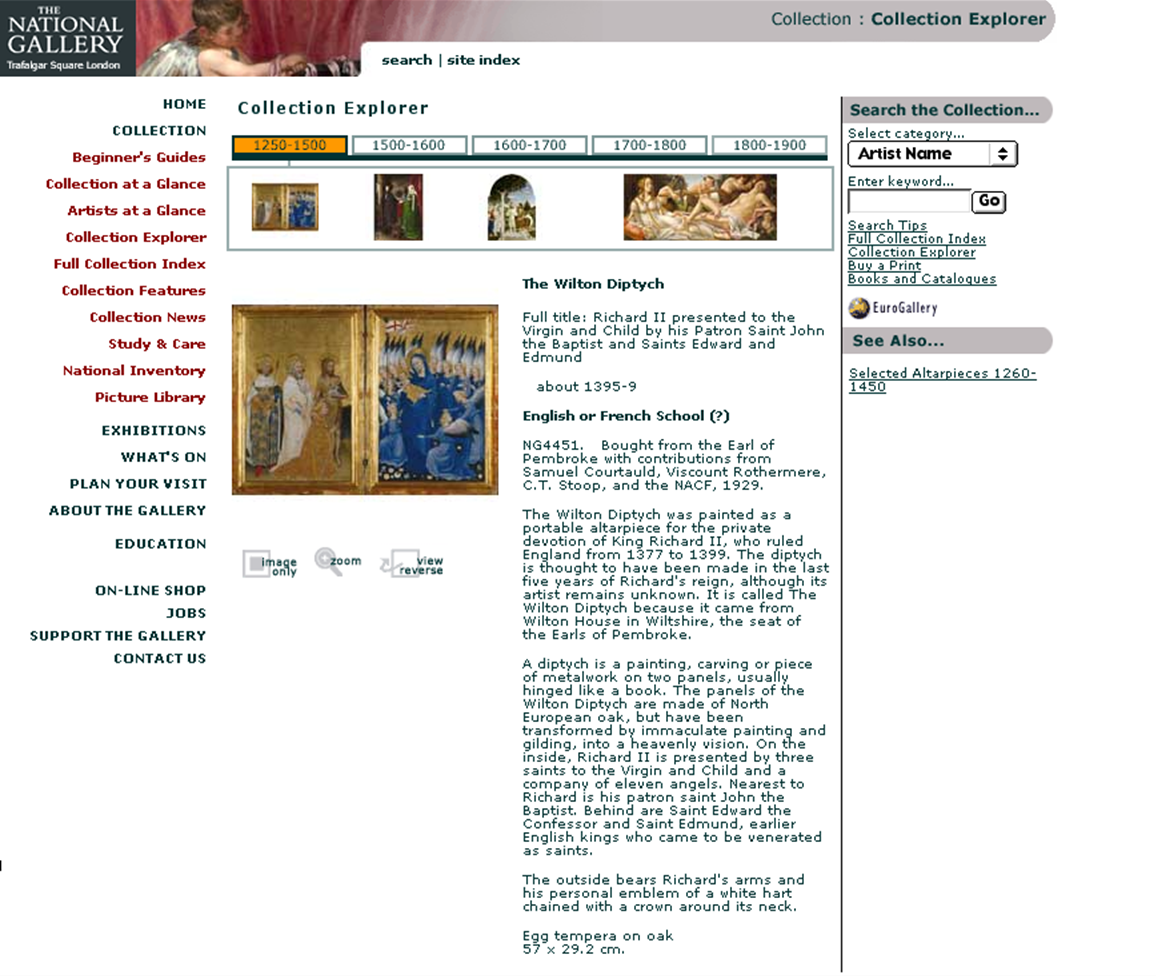
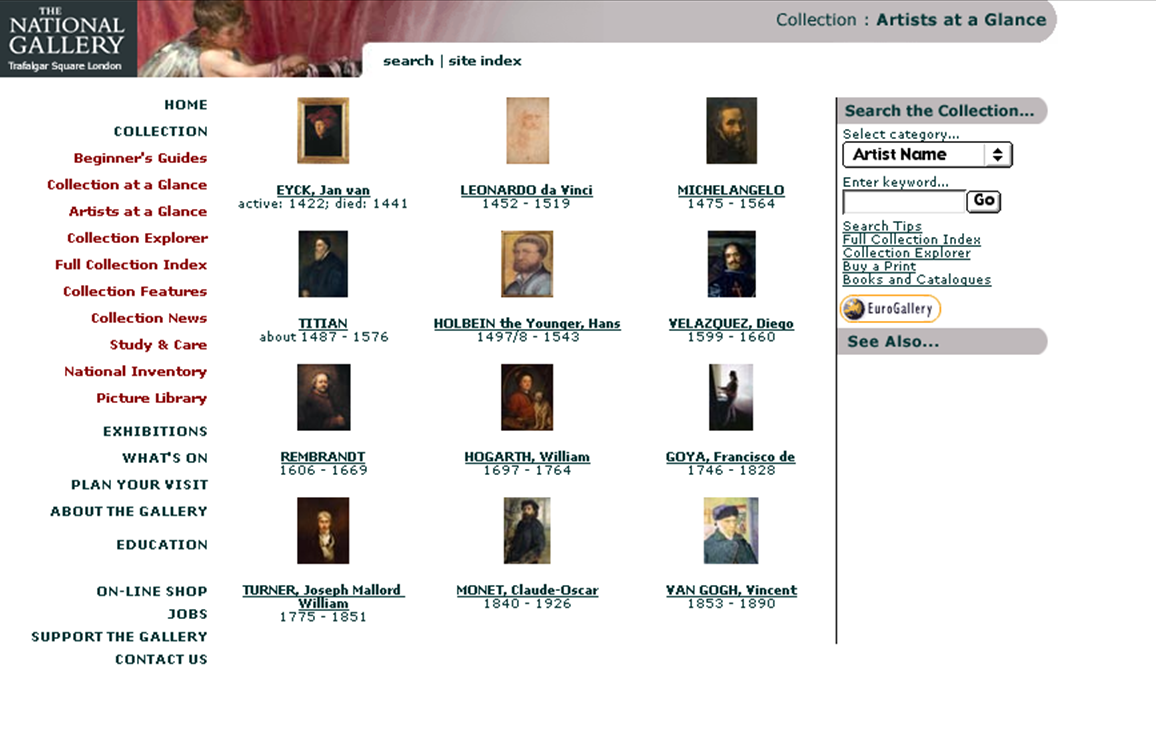
The site‘s basic organisation was similar to the Micro Gallery’s: paintings were accessed via artists’ biographies, glossaries, timelines, and thematic groups such as saints, altarpieces, monsters, etc.
This was again a standalone system: collections content was stored in an internal database, and updated manually from lists of changed data.
ArtStart

By now the Micro Gallery was over ten years old and showing its age. In 2003 the Gallery commissioned a replacement system from Nykris Digital Design.

ArtStart was launched in February 2005, with twelve kiosks in the space that had been occupied by the Micro Gallery, four more in the Sainsbury Wing, and further kiosks installed in our ground floor coffee bar later that year.

The system was seeded with content from the website, but further texts were added, notably for 30 highlight paintings and 30 key artists – as well as a significant amount of audio and video content. It was shortlisted for a BAFTA Interactive Award in the Design category in 2005 [scroll down the page].

Like the Micro Gallery, ArtStart was always envisaged as a part of a visit to the Gallery, independent of any website. The collection was again reached via artists, places and times, and themes and tours, each of which led to the detailed information on the paintings.

Users could print off a tour based on the paintings they had looked at – or email information to themselves. The system also included more general information, such as events that were being held on the day, or the Painting of the Month.
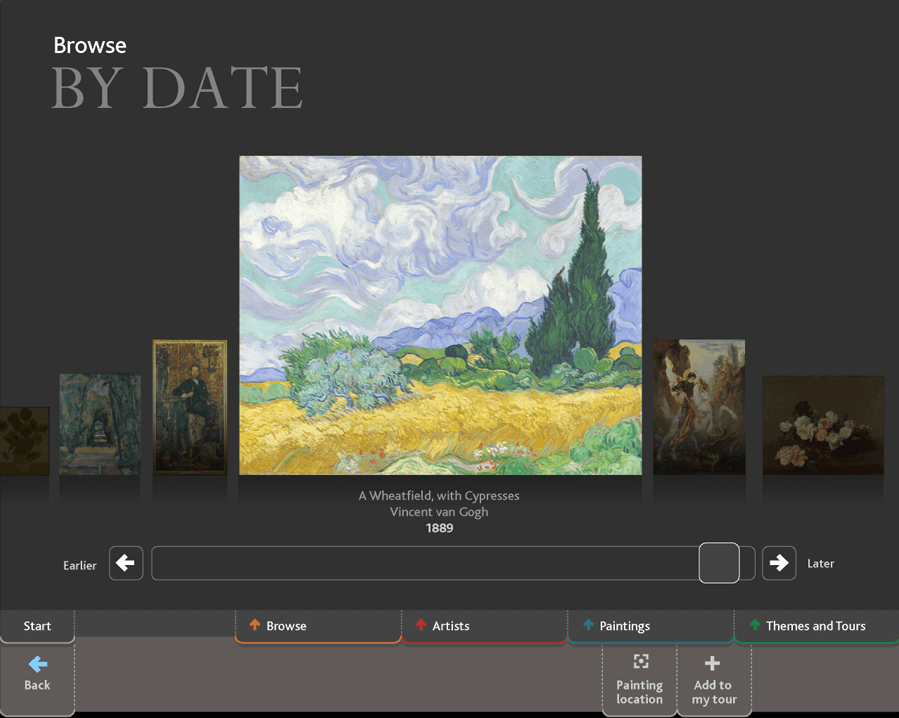
ArtStart was built in Macromedia Director, with an underlying SQL database. Each terminal was free-standing, with an additional machine holding the master data that could be pushed out to the individual kiosks. Painting locations and upcoming events were updated automatically from source databases, but the rest of the data was updated by hand by the New Media team.
Databases
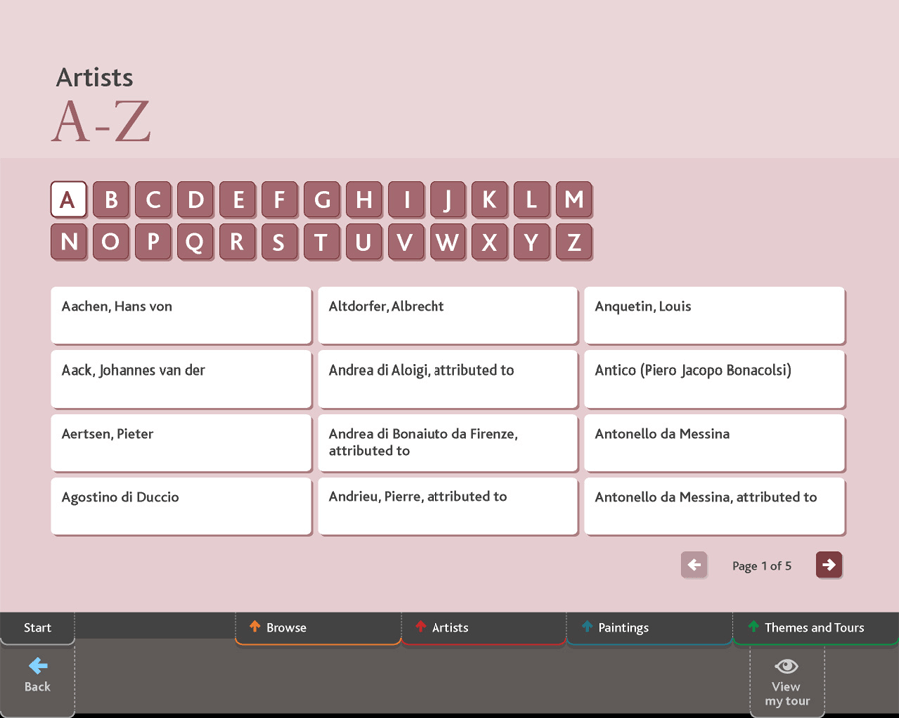
Index+
So what about a collections database? Before I left the Gallery in 1993 to start a PhD, I was part of a small group who were looking at possible systems. As far as I can recall – this was over twenty-five years ago – we looked at Cuadra STAR, DS Calm, iBase and Index+. Of these, the Gallery decided to implement System Simulation‘s Index+, and this eventually went live in 1994 or 1995, holding information and texts drawn from the Micro Gallery. It seems that the Gallery initially conceived of Index+ as a system to aid the digital publication of the collection, although it soon evolved to record painting locations, loans, exhibitions, and frames. It was managed by the Chief Registrar, but individual departments were largely left to work with the system as they saw fit; crucially, there was no centralised authority control.
TMS
For reasons which I’ve not yet been able to determine, the Gallery decided to replace Index+ after a few years. We settled on TMS, and became, I believe, Gallery Systems’ first UK client in 1999. Data was exported from Index+ to spreadsheets, where it was cleaned, and then imported into TMS. During the transfer, location history and frame data were identified as being too poor to be worth cleaning, and were dropped entirely from the import; but loan and exhibition histories were added by hand. We went live in 2000.
But the same problems that affected Index+ initially affected TMS: there was no single person owning the system or able to impose coherence on the data within it, which meant that the paintings’ tombstone data was unreliable, and multiple entries existed for the same people and organisations. The data was so inconsistent and undependable that it could not be used to support collections management procedures, and there was no incentive to use it to drive other systems.
All this began to change in 2001, when Gillian Essam was appointed to the newly-created post of Collection Information Manager. She took over the front-end administration of TMS, and also assumed responsibility for data analysis and reporting, starting the process of drawing up consistent, shared Crystal Reports.
Gillian also began working on our data. She set up a series of authority lists for individual fields, and tidied the Location authority. She took over data-entry from individual departments, so that information was entered as soon as it became available and to a single standard. She also set up a project to bring all the tombstone data within TMS into line with the Complete Illustrated Catalogue, which ran from 2003 to 2004. This consistently numbered groups of paintings (series like Hogarth’s Marriage A-la-Mode, or the individual panels of polyptychs), created short forms of titles where necessary, and recorded acquisition credit lines. At the same time, the Gallery’s small History Collection of material related to, but not part of, the main collection was added to TMS. And in the spring of 2005, all images in TMS were replaced with derivatives from our MARC high-resolution digital cameras.
As a result of Gillian’s efforts, by the mid-2000s the Gallery had in TMS a single, authoritative source of core digital collection information. Consequently, we were also able to share that data, and so used eMuseum – again configured by Gillian – to give staff access to our digital collection information through a web browser.
Collections Management
It was at this point that the second of the people I mentioned at the start of my lecture becomes important. Tim Henbrey was appointed as Head of Collections Management in 2005, having worked with TMS at both Tate and Gallery Systems.
Looking at TMS, Tim saw that it was being used to record what had been done to our paintings – but not to help us manage the various things we did. He therefore undertook a thorough review of the Gallery’s key processes – object movements, loans in, loans out, and exhibitions.
This led to a thorough overhaul of TMS to support these procedures, creating new data-entry views, list views, and Crystal Reports, and establishing clear data-entry standards and guidelines, on top of those which Gillian had drawn up for the paintings themselves. And finally, Tim instigated a couple of data-cleaning programmes, rearranging our departments, changing them from a short-hand for object statuses to headings that reflected the collections’ organisation; and making sure, with the help of the Dossier Assistant and a de-duping tool created by our IS department, that the Constituents module provided proper, unique, and controlled records to support our loan and exhibition processes.
Now these changes were made in, at the latest, TMS 9.35. I’m not certain what modules and tools were available then, but in Tim’s procedures, we make no use of the Insurance and Indemnity tabs in loan-related records, we don’t use any of the Containers or Conservation functions, and workflows are managed using a series of Thesaurus-based Statuses and Attributes – Jon tells me that Flex Fields only arrived in TMS 2010.
Notwithstanding, by 2011, TMS had changed from being an additional burden on staff, requiring them to enter data after the fact, to actively helping them manage their work and the Gallery’s paintings.
Data presentation after TMS
A web Content Management System
With TMS containing reliable information at last, and no doubt spurred on by the success of ArtStart, in December 2005 the Gallery began work on the development of a new website. This took three-and-a-half years, with the new site, developed by Box UK using their Amaxus content management system, going live in June 2009.
Our online collection data was, finally, driven by TMS: bespoke scripts extracted data twice a day from views developed for the website and uploaded it to Amaxus, where it was cached to drive the site’s own search and delivery systems. This meant that painting tombstone data and – crucially – locations would never be more than a few hours old.
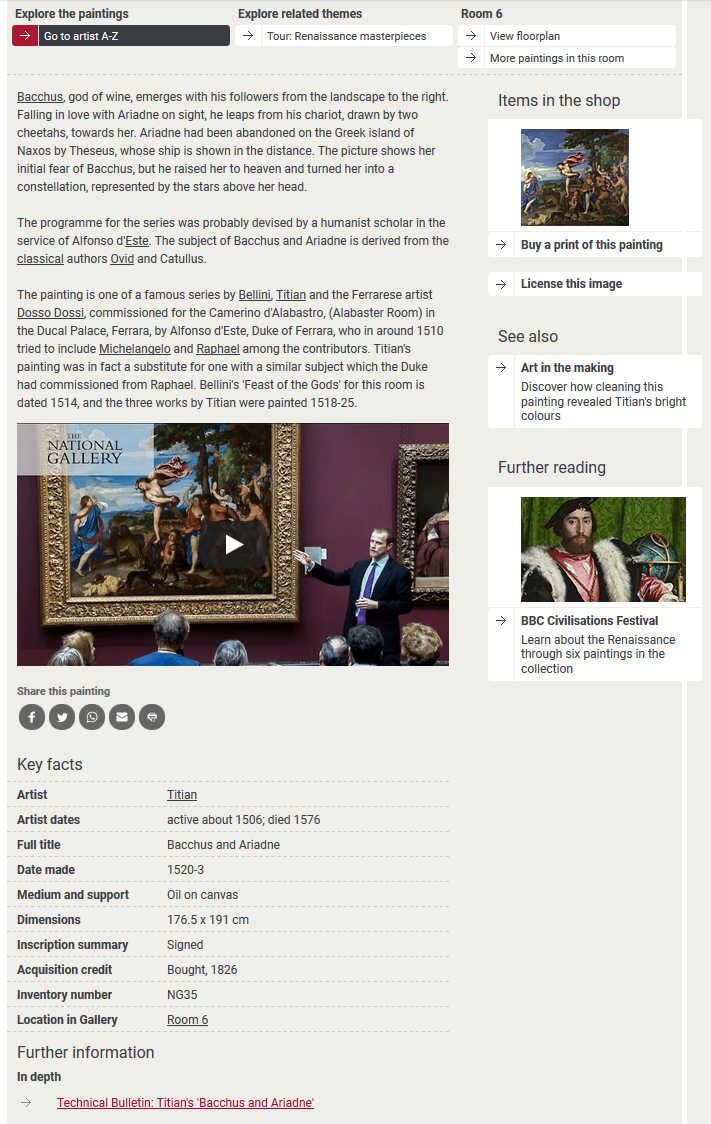
However, the narrative texts that explained and interpreted the collection were not stored in TMS, but within Amaxus itself – meaning that no-one save the web team had easy access to them, and they could not easily be repurposed and shared. The same was true of all the other painting-related content developed in Amaxus.
The Amaxus system was eventually retired in 2017, replaced by a new system developed within the Gallery that recreated Amaxus’s look-and-feel and functionality using the Umbraco CMS.
Intranet
Whilst the Amaxus public website was under development, Tim was investigating how to enable departments to share information across the Gallery – for example, allowing Information Desk staff to see future exhibitions. Our internal online collection information, which was still being delivered by eMuseum, wasn’t doing this, and more importantly, the list of fields which eMuseum could provide was not enough to meet our needs.
The Gallery therefore developed a new intranet, launching Portico in 2010, the year after the Amaxus website went live. Collection information was at its heart, drawn more-or-less directly from a set of purpose-built views in TMS.

Separate areas contained exhibition-related and paintings information, whilst a navigation bar on the left of the paintings page provided access to a wide range of different kinds of information about the painting, drawn from TMS or delivered via PDF and Word files linked to the Media module. The intranet also incorporated website texts drawn from Amaxus (and later Umbraco), and links to painting-related records in our archive database, Calm; our Collection Image Database, CID; and our DAMS for non-collection images, Portfolio.
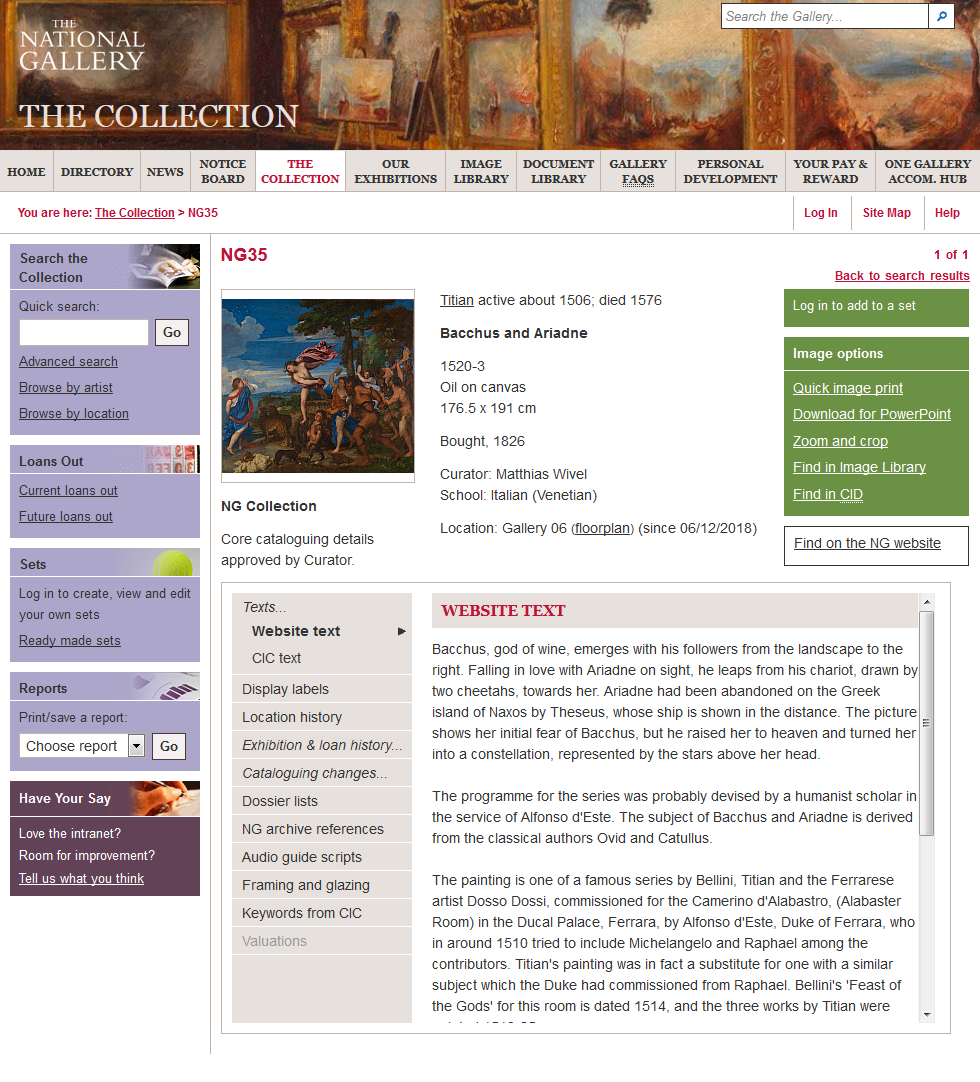
Cataloguing after TMS
The data that populated TMS has its origins in the Micro Gallery. Neither that, nor ArtStart nor our website, were intended to be a digital catalogue. To use today’s terminology, all these systems were a medium for engagement.
And so even the intranet, although it contains collections management-related information – framing notes, cataloguing change records, and so on – or raw data – linked Word and PDF files – is fundamentally based on the tombstone data held in TMS, tidied by Gillian in the early 2000s. This was what we needed to support Tim’s new collections management procedures. But if we return to what that tombstone data looks like on our website, you couldn’t say that it provides a rich digital description of the object, and it certainly falls far short of the entries contained within our new series of paintings catalogues.
I gather that we raised the possibility of expanding TMS to include rich catalogue information in the mid-2000s, and again in 2008, when the New Media Department discussed adding bibliographies and provenances to the website. Gillian therefore worked from 2008-11 on plans to provide detailed digital catalogue information, investigating similar projects coordinated by the Getty, and taking place at Tate – but to no avail. The impression I have is that the Gallery simply saw no reason to provide detailed catalogue information in digital form. Our print catalogues are subsidised by very generous donors, so we had no impetus to save money by no longer producing them; more importantly, we seemed absolutely wedded to the notion that only print could be an authoritative and credible source of information. Digital just wouldn’t cut it.
Austerity
And the time was wrong for a major project working on collection data. The banks had crashed in 2008, and the Conservative government had been elected in 2010 promising austerity – and delivering it. The National Gallery, a publicly-funded institution, was not immune. 2011 saw a series of reorganisations, frozen posts, and redundancies as we tried to cut back our spending. Among the casualties were the posts of Head of Collections Management, and the Documentation and Dossier Assistants. This left Gillian to support the Gallery’s digital collection information on her own – and as many of you know, just supporting TMS and its users can be a major task. Any plans for radical improvements to our digital collection data had to be put on hold. Similarly, we just did not have the resources to reconfigure TMS to keep up with changes in our procedures, and to exploit new features as they were added to the system, to the extent that people are again starting to see it as a hindrance rather than a help.
Our public-facing systems, too, felt the pinch: by the mid-2010s, ArtStart was becoming very difficult to maintain, and in 2014, we took the decision to switch the system off. The kiosks were removed overnight, and for the first time since 1991, there was no on-site digital interpretation of the Gallery’s paintings.
The Collections Information Project
A new Director

And then, on 17 August 2015, Gabriele Finaldi arrived at the Gallery as its new Director, keen to share our digital collection information with a much wider audience. Speaking on national television in January 2016, he said:
[T]he Gallery has probably more knowledge about its own collection than any other museum in the world. That’s knowledge that we want to share, it’s knowledge that we want to put out on the internet.3
That sounds like a boast – but remember all those published catalogues, never mind other publications. We really do know a great deal about our objects: this is a diagram I drew up a couple of years ago of the different forms of data we could conceivably present about a single painting.
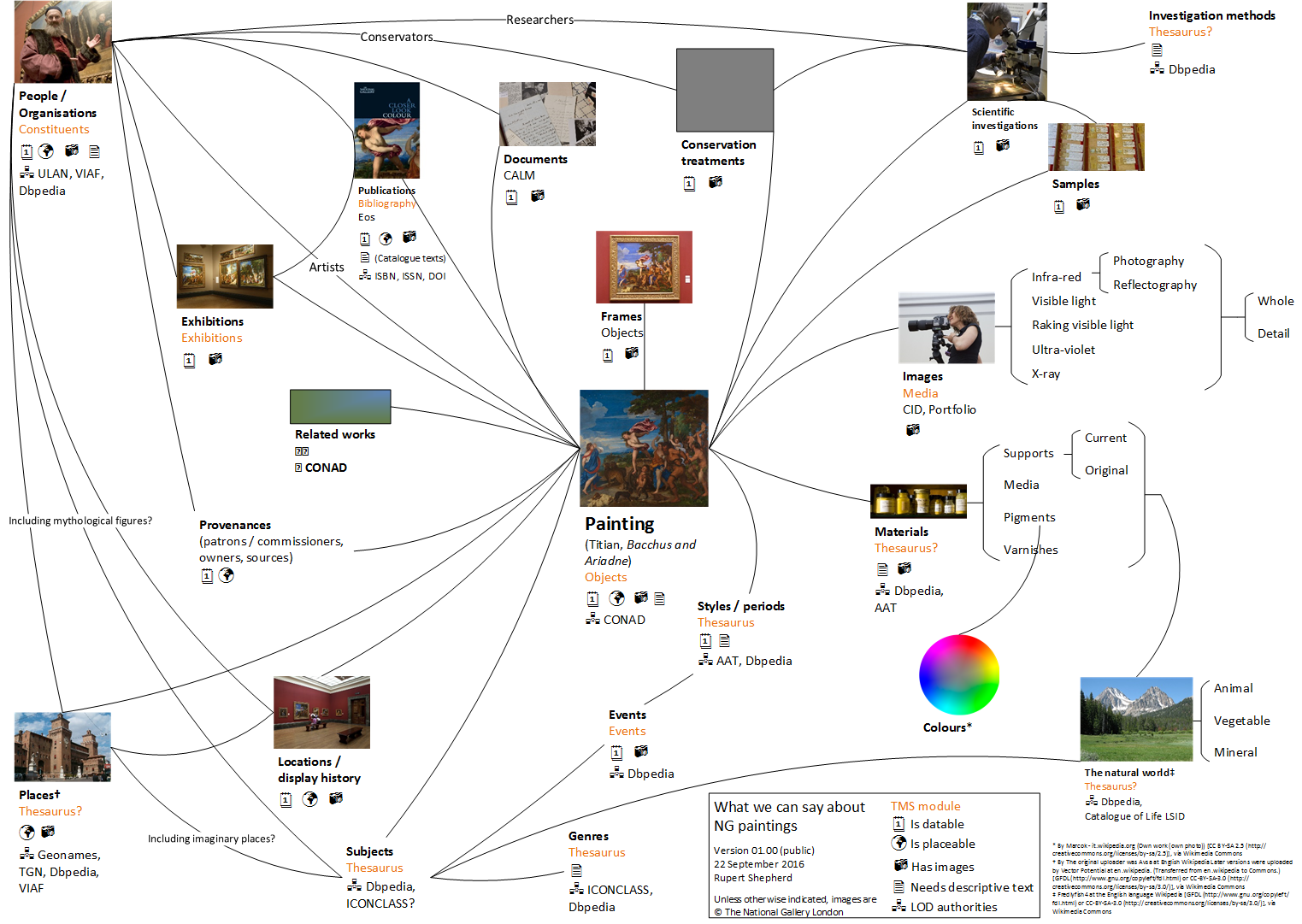
But delivering all this is not as simple as it sounds. If we want to showcase the depth of our knowledge about our paintings, the list of digital paintings data that we have in TMS and that might be used for a rich online resource is comparatively limited; particularly when you look at what data is actually useful. We’re missing several quite vital things:
- Provenances, even as chunks of narrative text
- Bibliographies
- Detailed information on materials and techniques
- Links to structured information – really, authority files – which would enable us to establish links between objects which are related to the same concepts for
- Materials and techniques
- Sitters and former owners
- Places where our paintings were made and owned or displayed, or which they depict
We also have no established links between paintings and related material in other databases; and our texts, in Umbraco, cannot easily be reused and shared – as well as being old, of variable lengths, and not particularly engaging.
The way forward – the CIP
Texts
How are we addressing this? We are now about two-thirds of the way through our major Collections Information Project, or CIP. Generously funded by an external donor, the project’s primary focus is those web texts. We are rewriting the texts for every painting, producing a short text of about 150 words and a longer text of about 500 words. As well as a project manager and technical staff, we’ve recruited six full-time equivalent authors and 1.6 equivalent editors to work on the texts, which are all being written for a ‘general audience’, using the Gallery’s new tone of voice.

Rather than use TMS’s Text Entries fields to manage the editorial process, we’ve created our own authoring system, based on a simple wiki program, DokuWiki, and we use this to write and edit the texts. It lets individual project members keep track of the texts that are allocated to them at any stage in the process; and crucially, it is easy to harvest the texts for use in other systems.
Data tidying …
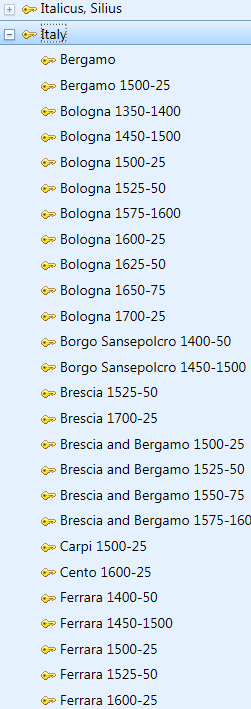
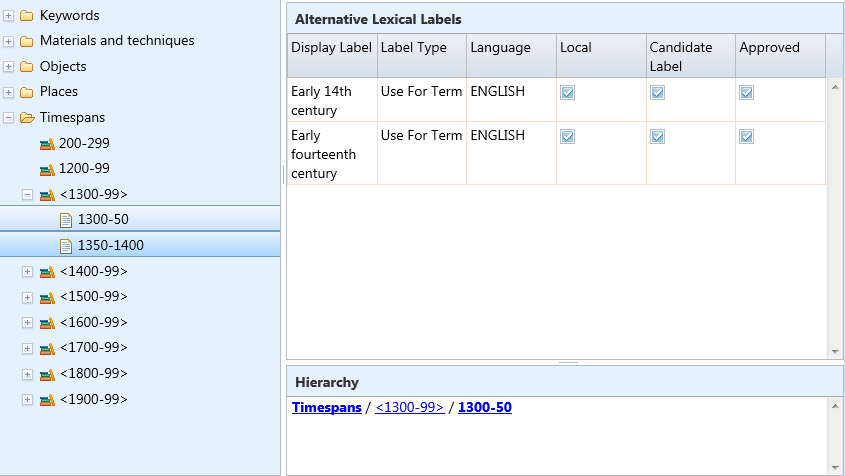
You cannot have an effective website, enabling users to browse and search the collection easily, without structured data. We’re therefore tidying the keyword data that was imported into TMS’s Thesaurus modules as a more-or-less flat file drawn from the index to the text of a CD-ROM version of the CIC. We have rearranged them into a series of concept schemes – keywords, materials, places and timespans – and begun arranging them in proper hierarchies.
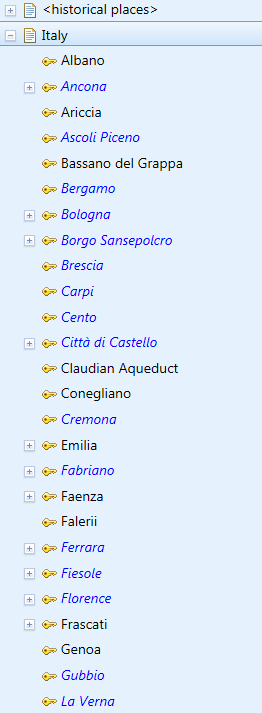
We’re reviewing the keywords attached to individual paintings, and already have an accurate timespan – a fifty- or twenty-five-year period – allocated to every painting.
… and wrangling
We’ve also employed a data wrangler to try and automate the extraction of structured data from several thousand Word files – notably the bibliographies from the dossiers. She used Python to turn the Word bibliographies and exhibition lists into about 35,000 records in spreadsheets; we’ve been tidying these by hand, aided by the quite powerful clustering tools in OpenRefine, so that we can upload them to TMS’s Bibliography module.
Catalogue digitisation
Given the Gallery’s investment in its print catalogues as the fundamental source of knowledge about the collection, we’ve also digitised all the catalogues that contain a current entry for a painting; these go back to 1957. We’ve created PDFs, and XML files structured using the Text Encoding Initiative data standard. Once we had the data tagged in XML, our data wrangler was able to write stylesheets that have allowed us to extract individual chunks of text – say provenances – and process them for upload to TMS.
Data entry
The provenances extracted from the catalogues vary greatly in their arrangement, and so the project’s data-entry assistant began to edit them all into a consistent format. (I set up some Flex Fields to track the status of each entry.)
Library catalogue
But there’s also the problem of collection-related data held in other systems – notably our Eos library system. We appointed a Library Cataloguing Assistant for six months to make sure that there was a record in Eos for all Gallery publications – and list the Gallery’s paintings which featured in each of our exhibition catalogues – so that we could, if necessary, pull these into TMS using the Z39.50 importer – although, for various reasons, this is less easy to use than I would like.
Middleware
So we have data in TMS – and also in the Calm archive management and Eos library management systems; our two image databases, Portfolio and CID; and the folders that contain the collection images.
But how to join all this data together, and deliver it seamlessly to the various consuming systems? Our solution has been to procure something to sit between these data sources and data consumers, taking data from all the sources, aggregating it, and presenting it as a single source via a series of endpoints delivering different formats. We chose Knowledge Integration‘s Collection Information Integration Middleware, or CIIM.
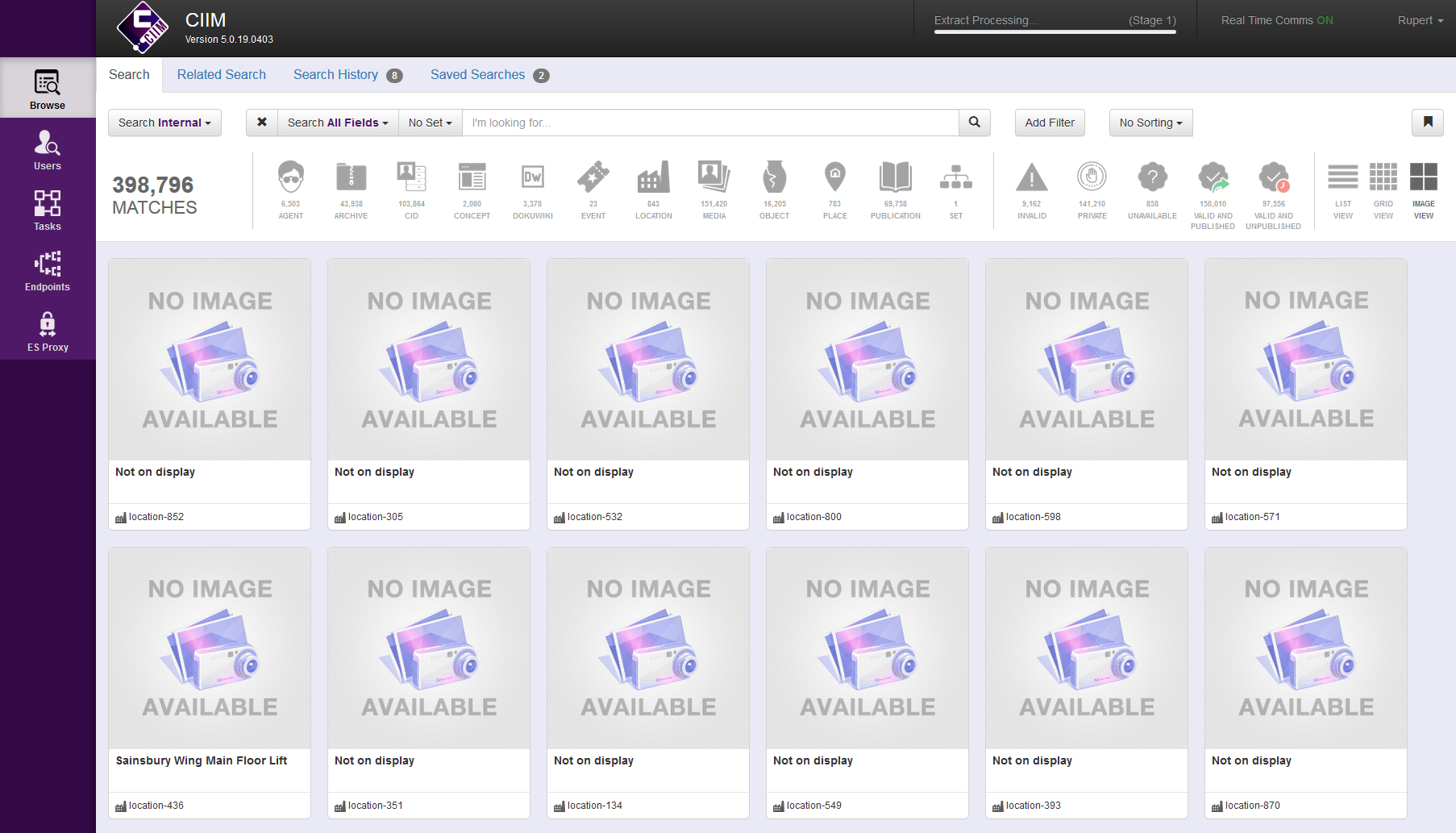
This takes data from all these systems – as well as our DokuWiki authoring system and our Artifax room booking database – links it together, standardises it, and presents it in a web-based user interface for review and, if necessary, augmentation. It then outputs it as JSON via an Elasticsearch endpoint.
Here, again, is our current set up.
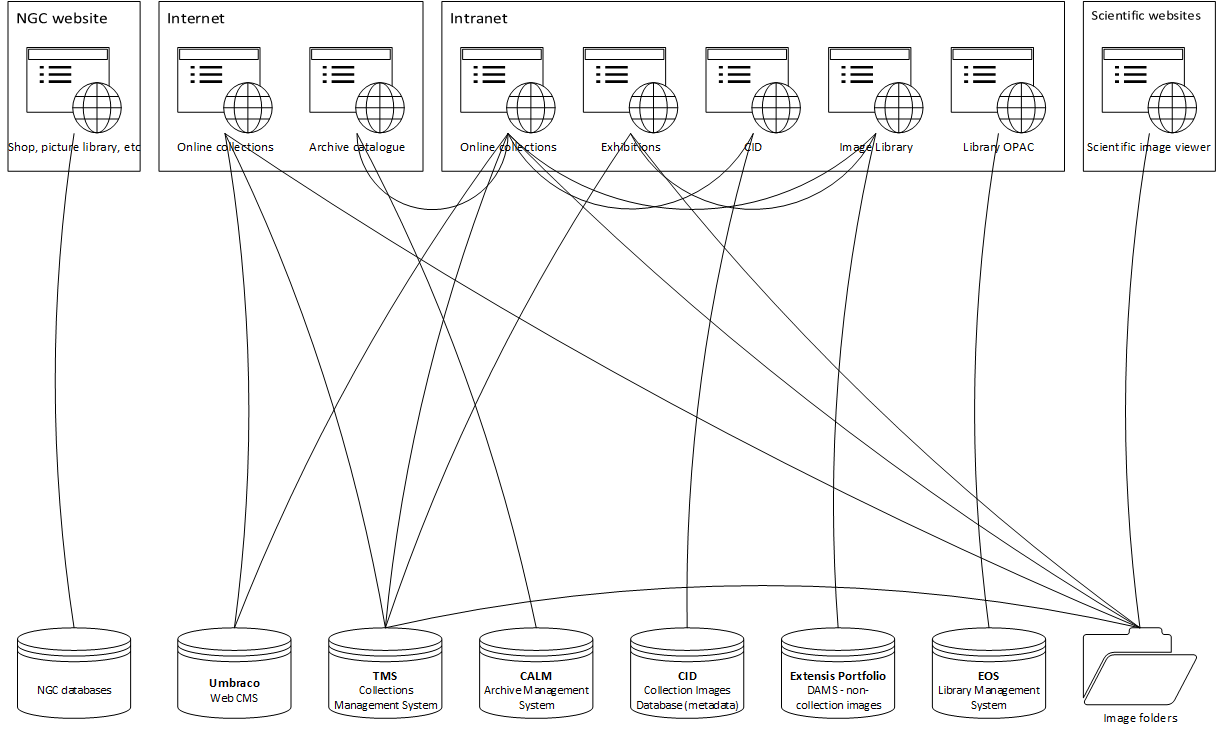
Along the bottom are our data sources,
- National Gallery Company databases
- Umbraco
- TMS
- Calm
- CID
- Portfolio
- Eos
- And collection image folders
Along the top are the various systems that consume the Gallery’s collections data:
- The National Gallery Company website
- Our main website, with separate sections for
- The collection, and
- The archive
- The Gallery’s intranet, with pages for
- The collection
- Exhibitions
- CID
- The ‘image library’, i.e. Portfolio
- And the library OPAC, drawing on Eos
- And over on the right, the viewer for scientific images maintained by our scientific department
The lines indicate all the different, direct, and usually handmade links between these systems.
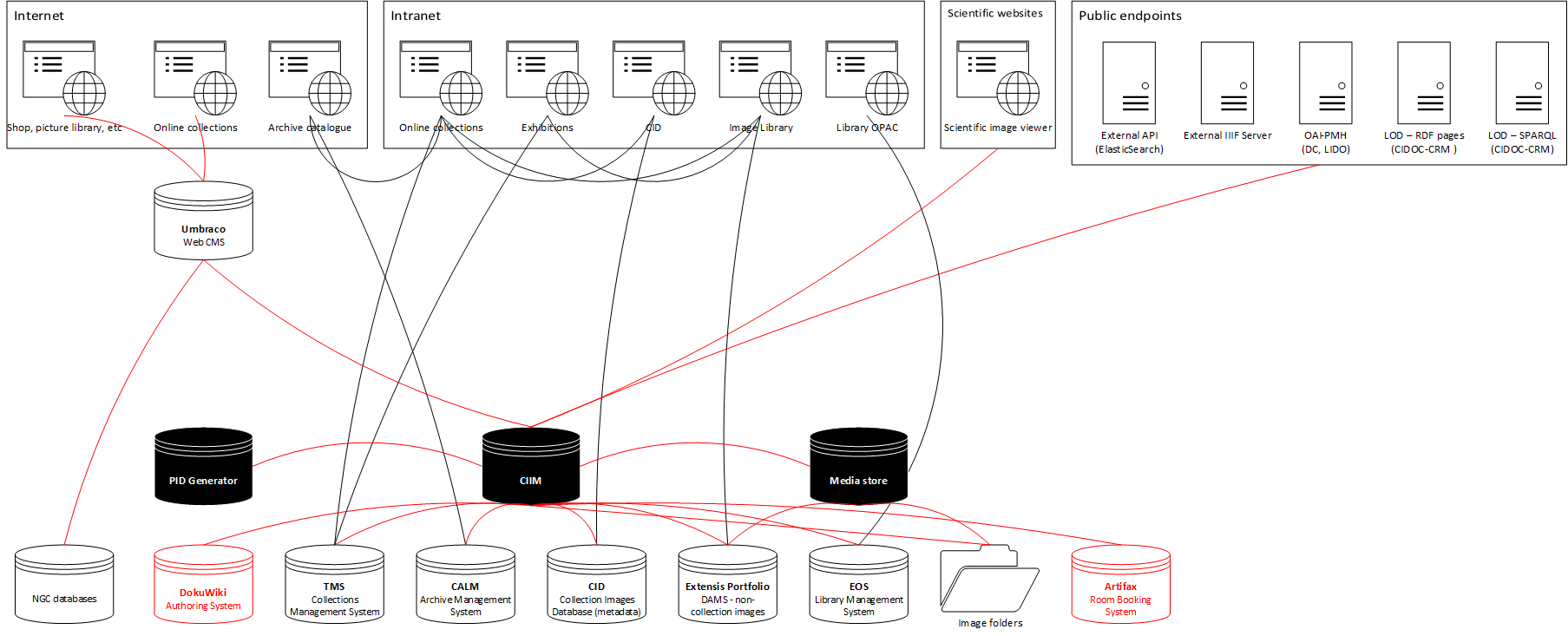
And this is what it will look like after the first stage of our CIIM implementation. You can see the CIIM’s three data stores:
- A system for storing persistent identifiers, used to deliver unique, ‘cool’ URIs to drive linked data
- The CIIM itself, for collection data
- An IIPImage server for images
These feed into an Elasticsearch-based API that feeds our Umbraco web CMS to drive our new online collections. They also provide data to a series of interoperable public endpoints:
- A version of our Elasticsearch API
- An external IIIF server
- An OAI-PMH server delivering Dublin Core– and LIDO-formatted data
- Individual pages containing Linked Data representations of our collection in RDF/XML
- A SPARQL endpoint
We’re building these to serve data to research projects; we’ve also begun discussions with Google Arts and Culture and ArtUK about using interoperable endpoints to keep their versions of our data up to date, rather than continuously sending them spreadsheets.
The diagram still looks quite complicated, because this is only the first stage of converting our systems to draw only from the middleware. Our final goal is to drive all systems that consume collections-related data from the CIIM.
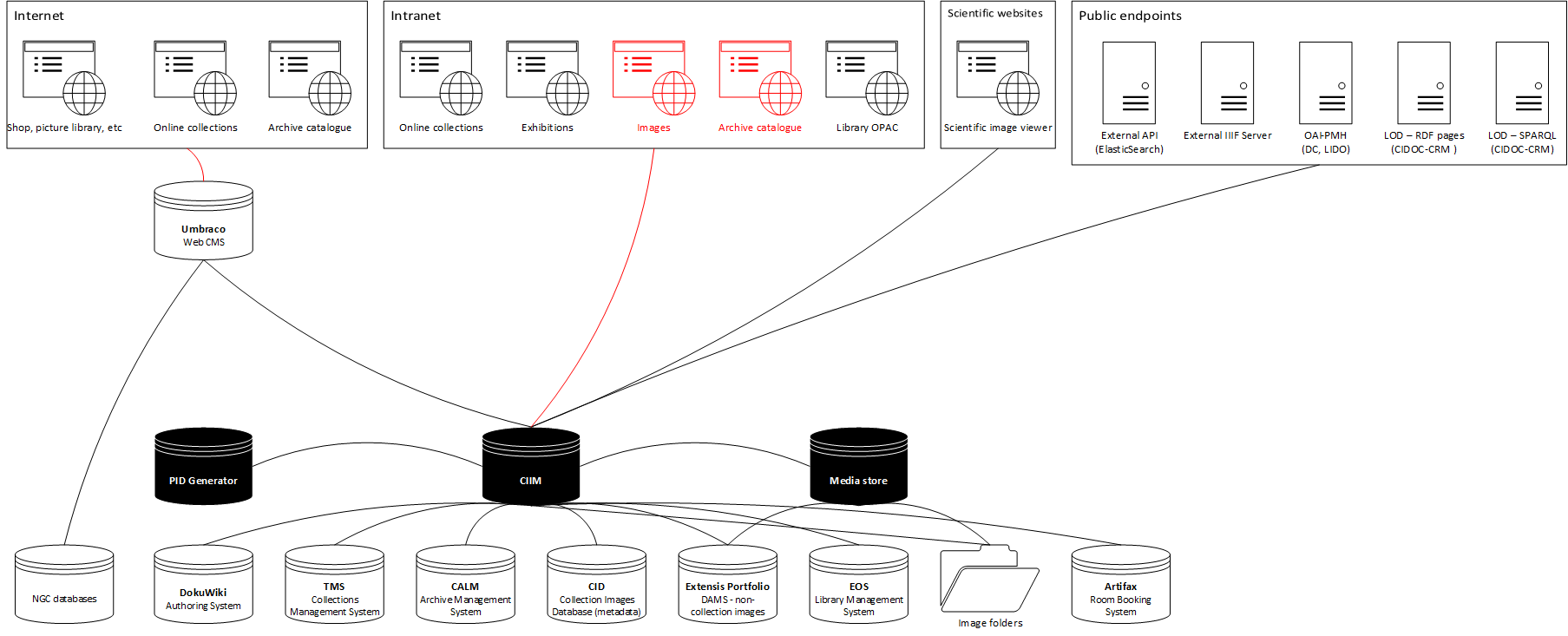
Collections management
And what does the future hold for TMS at the National Gallery? Tim Henbrey did sterling work in aligning TMS with our procedures before he left in 2011, but due to lack of staff – since 2011 the Gallery’s only had one post responsible for collection data day-to-day – the system has not been reviewed to ensure that it reflects our procedures as departments are rearranged and processes changed to support our ever more ambitious programme of exhibitions, loans and redisplays. The system has now reached the 2018 release (we’re on 2016 R2), and there’s a significant amount of functionality – notably Flex Fields – that simply wasn’t available when Tim was carrying out his work. We need to be able to take advantage of these new features to ensure that TMS continues to help us in our work, rather than being a hindrance.
I’m delighted to be able to say that the Gallery will soon have a second member of staff working on collection information in general. Some of you, attending the pre-conference workshops, will already have met Hugo Brown, who will join me on 29 April as the Gallery’s Collection Information Officer. As soon as he is familiar with the system, Hugo will be working with our Exhibitions and Registrars’ departments to review their procedures and embed them in TMS.
‘A digital dossier for every painting’
Our new collections website will go live in a month or two; the CIP will finish in mid-October; and Hugo is poised to start reconfiguring TMS. What next?
First, we will need to maintain the richer level of detail that we are delivering as a result of the CIP. We will incorporate adding keywords and web texts, and keeping them up to date, into our standard data checks for new objects and our procedures for managing changes in core object information in the light of new research.
We will also need to resume logging references to the Gallery’s paintings in newly-received publications – something we haven’t done for about seven years – and I hope we can pilot this with a new Collection Information Assistant in the new financial year – assuming my bid has been successful.
In addition to this, the Gallery’s current five-year strategic plan includes this item:
By March 2023: Development of the existing Collections documentation into a digital research resource that could be consulted by visitors to the Research Centre and that would function as a ‘digital dossier’ for each painting
We’ve begun to scope what this might mean, and will begin more detailed planning, before running some pilots, as soon as the CIP finishes. Clearly, it will have its challenges: we have a vast amount of data available to us, most of it either analogue or unstructured.
Building upon what we will have done for the CIP, we could:
- Write new web texts for artist, sitters, subjects and glossaries
- Clear our backlog of unrecorded bibliographic references
- Record more detailed information about materials, particularly pigments
- Enrich our exhibition histories with installation images and catalogue details
- Add keywords from our commercial Picture Library and ArtUK, and subject-index the whole collection again
- Link all our authority records to external Linked Data authorities to render them properly linked and interoperable
- Collaborate with a proposed project on the provenance of all our paintings, completing the reformatting of our provenance texts and converting them into structured data (I have my eye on Carnegie Museum of Art‘s Elysa tool, developed for the Art Tracks project, which will take a well-formatted provenance text and turn it into structured data)
- Digitise the catalogue entries for new acquisitions contained in our annual reports
- Proofread the OCRed catalogues, and refine the XML markup for all the digitised catalogues, embedding cross-references and expanding abbreviations, and clear rights in the images needed to publish the entries online in full
And there’s scope to expand our coverage, too. We could:
- Digitise the unique material in the dossiers, and record links to material elsewhere
- Digitise the archive records which are most relevant to the paintings, notably our inventory and our manuscript catalogue, which was maintained from 1855 until 1955
- Digitise more old catalogues, from the CIC back to the very first, in 1824, and wrangle changes in attribution, date, and title from the digitised texts
- Link painting records to old labels, audio-guide texts, videos and podcasts
- Record and digitise the remaining analogue collection-related photographs
- Extract paintings’ previous locations from old guidebooks and catalogues – these go back to the last century, and can give us a history of how the collection was displayed
- Digitise and incorporate our conservation dossiers and scientific records
- Include works that were once in the collection – notably the British paintings now in Tate
- Expand coverage to include the history collection and our frames
How much we will be able to do remains to be seen; but whatever happens, TMS, the CIP, and our middleware, should have given us a solid foundation on which to build.
Conclusion
We’ve come a long way from our post-War paintings catalogues and our twelve standalone kiosks presenting information created as a one-off for public consumption. Along the way, we’ve seen systems come and go (TMS has lasted the longest!), and a gradual decline in the breadth and depth of the information that we deliver to our users outside the Gallery; we’ve lost the leading position that the Micro Gallery once gave us. Lack of resource has led to systems becoming less useful for our internal users. But I’m confident that, with a soon-to-be-reconfigured TMS at the heart of our infrastructure, the National Gallery is now poised to make significant advances in the data that we offer to all our users, and I hope we will soon regain our position in the vanguard of institutions sharing their digital collection information.
Acknowledgements
I’m indebted to the following for generously sharing their knowledge and time, and for supplying images:
- Annetta Berry, former New Media Editor, The National Gallery
- Gillian Essam, former Collection Information Manager, The National Gallery
- Tim Henbrey, former Head of Collections Management, The National Gallery
- Alex Morrison, Managing Director, Cogapp
- Len Nunn, Head of Information Systems, The National Gallery
- Paul Sheffield, former Interactive Designer, Nykris Digital Design
Any errors are of course my own.
Updates
This is the text as delivered, with the addition of hyperlinks and footnotes, and a few very minor emendations:
- Names expanded in first paragraph
- Title of Judy Egerton’s catalogue corrected to British School
- Date ArtStart was switched off corrected from 2015 to 2014
- Periods covered in timespans changed from 25 years to 50 or 25 years
Notes
- National Gallery, ‘Micro Gallery Pioneers New Approach to Museum Information for Visitors’, 1991 [↩]
- ‘World Wide Web’, Wikipedia, 2019 <https://en.wikipedia.org/w/index.php?title=World_Wide_Web&oldid=888498711> [accessed 19 March 2019] [↩]
- Newsnight , BBC2, 4 January 2016 [↩]