
In a normal year, museum staff manually copy the details of thousands of objects from their databases, and send them to other museums that wish to borrow those objects. The borrowing museums’ staff then manually copy those details back into their own systems. CIDOC’s EODEM project aims to make the whole process much quicker and simpler by establishing a framework that will enable museum databases to export objects’ data from one system at the press of a button, and import the data into another system as easily as possible. Project lead Rupert Shepherd explains how it will work, and some of the challenges encountered along the way.
Presented at Dynamic Information for Dynamic Collections (Collections Trust Annual Conference, 2020), held online on 1 October 2020.
There is a separate page on this site for resources related to EODEM.
I ’ll begin with an apology. We planned to demonstrate a working prototype of the Exhibition Object Data Exchange Mechanism, EODEM, at the CIDOC conference in Geneva, originally scheduled for a fortnight ago; and, having ironed out all the technical problems then, I would be delivering a polished, problem-free demonstration to you today.
Then … events happened, and everything’s been delayed. So instead, I will talk about:
- What we – the CIDOC Documentation Standards Working Group (DSWG) – are trying to do, and why;
- How we’re doing it;
- Some of the problems we’ve encountered;
- And our next steps.
What we’re trying to do …
Our aim is very simple: to make it possible to export object exhibition data from a lender’s collections management system at the touch of a button, and import that data into a borrower’s system – produced by a different software vendor – just as easily.
… and why
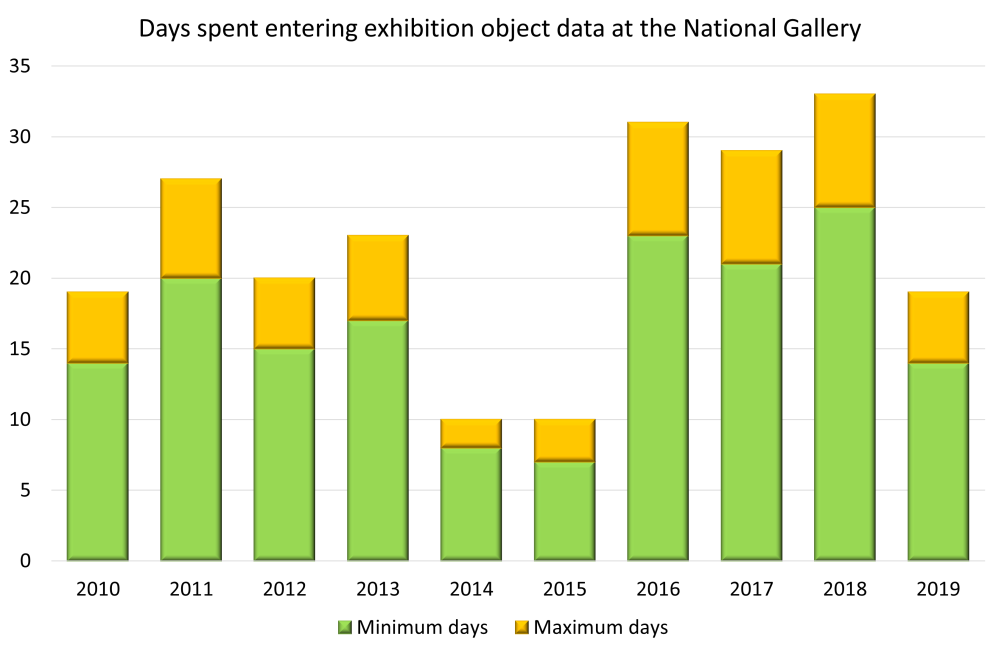
We want to do this because of the huge amount of time spent copying and pasting – or, worse, retyping – object information between collections management systems and forms or emails. But is this really all that time-consuming? Looking into the figures for the museum where I work, the National Gallery, our best estimate is that over the last ten years, we’ve entered an average of 405 loan object records per year into our collections management system (we use TMS).1 Making some practical assumptions, this equates to between 16 and 22 days a year entering exhibition object data into TMS – a total over the ten years of somewhere between 164 and 224 days: as a worst case, that’s an entire working year over the last ten years spent on data entry. And that ignores the work done providing information for loans out. Whilst we have a fairly ambitious exhibition programme, we’re not atypical of large museums.
And there’s another reason. Collections Trust currently lists 18 Spectrum Partners on its website. Looking at the list drawn up by the CIDOC Encyclopaedia of Museum Practice, we find 76 collections management systems – and that list is very euro-centric. Each system has its own data structure: they don’t speak to each other. Now, the smooth transfer of object data from one database to another has been the holy grail of documentation since at least 1990, when the Consortium for Computer Interchange of Museum Information (CIMI) was founded. Whilst we’re still not there yet, there have recently been positive developments – notably Art UK’s successful data harvesting pilot project, which Andy Ellis and Adrian Cooper will speak about tomorrow; Collections Trust’s own initiatives in this area, which Kevin Gosling will tell us more about tomorrow; and UKRI’s massive Towards A National Collection funding streams.
But these are all focussed on exporting data for presentation; they don’t tackle the fundamental aim of making collections management systems work with each other. This is non-trivial – but we hope that EODEM’s aims present a problem that is small enough to be solvable without too much effort.
How we’re doing it
So how do you develop something like EODEM?
The initiative emerged from conversations that I had with Jonathan Whitson Cloud, one of the co-chairs of the DSWG, during the 2016 CIDOC conference in Milan. Its formulation is still very much Jonathan’s.

We began by thinking about what data museums would need to exchange. At the next CIDOC conference, in Tbilisi, we organised a workshop with documentalists, challenging them to assemble lists of the necessary units of information.
The following year, in Heraklion, we organised a round table with various software vendors to discuss the viability of a data exchange mechanism, and to review the list of units of information which we had drawn up in Tbilisi.2The result was a consensus that the project was doable – and the first draft of the EODEM data profile.3

At that point, the process stalled as other commitments got in the way. Our initial plan, to have a demonstrator ready for the CIDOC strand in the ICOM triennial in Kyoto in 2019, fell by the wayside. But a small working group has evolved, comprising representatives from several software vendors and the DSWG.4 Other developers receive notes from our meetings, which have been happening regularly over the last year.5 We have been focussing on the definition of a final data profile, comprising:
- A final list of units of information;
- An agreed data standard with which to encode them; and
- An agreed file format in which to transfer the data.
Problems
So what problems have we encountered?
Units of information
The first is the variable level of documentation in many museums. Our current list of units of information numbers 28.6 I’d be very surprised if any museum could provide data for all of these. But we’re working on the principle that anything is better than nothing, and so the only mandatory units of information for an EODEM record are:
- Object Identifier
- Object Type
- Title/Name
- Lender Name
- Export Date
– and the latter two would be filled in on export, rather than needing to be stored as data. So we don’t need a source system to be set up to contain all these units of information.
The second problem is data granularity. We can illustrate this with a set of dimensions, say for a painting, which has height and width: 176.5 × 191 cm. This can be expressed simply as a string of characters; or it can be broken down into individual fields:
- Type =
height - Value =
176.5 - Unit =
cm - Type =
width - Value =
191 - Unit =
cm
I hope you’ll all agree with me that granular data is more useful. But what if our lender’s collections management system doesn’t have those granular fields? EODEM won’t force software vendors to add structured fields to their system, if they don’t already have them: it will accept an unstructured string. In fact, dimensions are one area that most collections management systems do break down into individual fields – but entering data like this is time-consuming; or perhaps users have only been able to cut and paste a string from an older system. And what about names? Or temperature requirements?
Well, many EODEM units of information include both a free-text field and a set of structured fields; the source system delivers whatever it can. Likewise, the developers of the receiving system will decide whether they want to try to parse unstructured strings into separate fields, or take them as is; or, conversely, take structured data and concatenate it into strings. It all depends on their own systems, and how much work they want to put in to EODEM.
Data standard
When it came to choosing a data standard to hold our units of information, we wanted something which was well-established, and had already been incorporated into at least some collections management systems. The obvious candidates were CIDOC’s standard for Lightweight Information Describing Objects (LIDO), which has recently been incorporated into several systems as part of the Europeana Inside project; and of course Collections Trust’s Spectrum, with which Spectrum Partners’ systems comply – although we were specifically interested in the interoperable version of the Spectrum standard, Spectrum XML. We reviewed our units of information against the current version of LIDO, 1.0, and – thanks to help from Gordon McKenna – the most recent version of Spectrum XML, 4.0.
However, neither standard contained all the units of information we required. LIDO, primarily designed to deliver data for aggregated online collections, lacked collection management information.7 Spectrum did rather better in this area, although more granular fields were often covered by a free text field, and some fields were still missing.8 But crucially, LIDO’s data model, which is based around events related to objects, seemed more flexible: we could create generic event types (like ‘display of object’, ‘transport of object’) and attach descriptions and measurements to them; so we chose LIDO as our data structure.
File format
This decision also chose our file format for us: LIDO uses the long-established and highly-flexible eXtensible Markup Language, XML.
Finalising the data mapping
In fact, some of our requirements contradict the LIDO standard. Luckily, it is in the process of being revised: a draft version 1.1 was issued for comment in April this year. We are extremely grateful to Regine Stein, the chair of the LIDO Working Group, who has been working closely with us, both explaining how to meet our needs using the existing standard, and taking our requirements back to the Working Group to see whether the draft can be revised.
Our problems lay in three areas:
As currently defined, measurements in LIDO are measurements of the actual object – length, weight, height, etc. But we want to record measurements that relate to the object’s requirements: the range of temperature, relative humidity, etc., within which it should be stored and displayed. The LIDO Working Group has agreed to extend the definition of measurements in version 1.1 to include requirements.
We want to tie these requirements to generic events, such as display, transport, etc.: not just for one particular loan, but for any display or transport of the object. But events described in LIDO must be specific, historical occurrences. However, the LIDO Working Group pointed out that our events can be considered in this way, if we conceive of them as being, not the object’s notional display (for example), but rather the assessment that took place to determine what its display requirements should be.
Finally, we’re still working out how to identify a group of sets of measurements which are all about one thing – for example, an object’s temperature requirements. We’re currently awaiting the LIDO Working Group’s imminent response to our latest proposal.
This collaboration has benefitted us both: we’ve helped make the next version of LIDO better by enabling it to record more information; the LIDO Working Group has been given a focussed use case to help inform their decisions; and we can be certain that EODEM data will adhere to the LIDO standard.
Next steps
So what next? Once we’ve received LIDO’s decision about how best to identify groups of measurements, later this month, we should be able to finalise our data standard. We’ll draw up a final version and a sample dataset, which we’ll circulate to the developers who attended the Heraklion workshop.
We will also use a workshop at the CIDOC conference, now rescheduled to December, to introduce the project to potential users – that is, museum collections managers, documentalists, and exhibitions staff.
We will present the new EODEM standard at another workshop at the CIDOC conference, for system developers, where we will discuss the steps required to develop the actual export / import mechanisms in individual collections management systems, and try and identify any problems or questions that might arise during the development process.
I expect one problem to be the way that people will want to use EODEM. Realistically, object data will probably be updated in three stages:
- first, when borrowers send out an initial informal enquiry about the possibility of a loan;
- second, when a loan has actually been agreed, and the lender has stipulated their conditions;
- and finally, when all preparation for the loan has been completed, the object’s measurements have been updated, requirements finalised following conservation, etc.
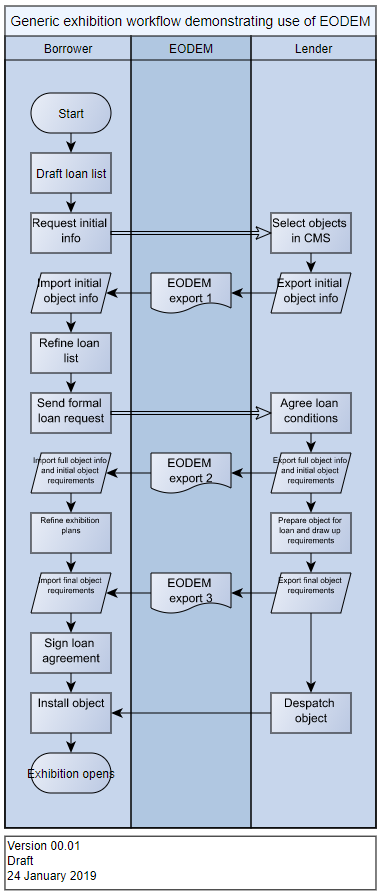
Consequently, the data for the same object needs to be imported several times, and the importing system has to decide each time whether to append a new record or update an existing one – and make sure that it updates the correct object’s data, if that is what it decides to do.
Related to this is the problem of aligning vocabularies – particularly important for makers’ names, as nobody wants to keep adding duplicate records for the same person into their database. So developers will want to include some mechanism for mapping imported terms to those already in the system. Hopefully, they can reuse existing tools for bulk imports.
Here, too, the adoption of the LIDO data structure is an advantage. Much of the LIDO model is based around combinations of text strings (in blue in the example) and identifiers (in red).<lido:actor>
<lido:actorID lido:source="ULAN">http://vocab.getty.edu/ulan/500026846</lido:actorID>
<lido:actorID lido:source="Wikidata">https://www.wikidata.org/entity/Q159758</lido:actorID>
<lido:nameActorSet>
<lido:appellationValue>Turner, Joseph Mallord William</lido:appellationValue>
</lido:nameActorSet>
</lido:actor>
If the identifiers use standard vocabularies, then a system could use identifiers, rather than the string, to match the term. We’re already thinking about exploiting this in the next version of EODEM.
But first we have to develop a basic working system. Subject, of course, to events, we should be able to give a live demonstration of the export of data from one system, and its import into another one, at CIDOC 2021 in Estonia. And, having ironed out all the technical problems then, I hope to deliver a polished, problem-free demonstration of the CIDOC Exhibition Object Data Exchange Mechanism to next year’s Collections Trust conference – if you’ll have me back.
Notes
- My colleagues tell me that it takes between 15 and 20 minutes to enter all the data for an exhibition loan in into TMS; I’ve assumed an effective working day of six hours – i.e. ignoring time spent checking emails, drinking coffee, and doing all those other things that make office life run smoothly. [↩]
- The workshop was attended by representatives of AltSol (Reasonable Graph), FORTH (DMS-OVS [Document and Procedure Management System for GNM Nürnberg]), Gallery Systems (EmbARK, TMS), JOANNEUM RESEARCH Forschungsgesellschaft mbH (ImdasPro), Knowledge Integration (CIIM), Ministry of Culture (Estonia) (MuIS), Modes Users Association (Modes), Musoft.cz (Musoft.cz), OpenHeritage (OpenHeritage system), Qulto (Qulto Manage), Rosphoto.org, Sistemas do Futuro (In arte online, In patrimonium.net), Unisystems GR (TMS agents), and Zetcom AG (MuseumPlus). [↩]
- Comprising: Item ID (1), URI (0–1), Object type (0–1), Materials (0–∞), Measurements (0–∞), Item count (0–1), Title/name (0–∞), Brief description (0–1), Dated (0–∞), Maker (0–∞), Image (0–∞), Lender (0–1), Credit line (0–1), Insurance/Indemnity (0–1), Value (0–1), Condition of object (0–1). [↩]
- Gallery Systems, Knowledge Integration, Modes User Association, and Zetcom. [↩]
- ArchiveTech.net / UniqueCollection.org, Userix Oy, CoMwork, and Vernon Systems. [↩]
- Specifically: Object Identifier, URI, Object Type, Materials, Measurements group, Title/Name group, Brief Description, Date group, Maker, Image, Credit Line, Insurance/Indemnity, Value, Condition, Temperature group, Relative Humidity group, Lux Level group, UV Exposure group, Handling, Transport, Installation, Condition Checking, Display, Security, Photography and Filming, Hazard, Lender Details, Export Date. [↩]
- Of the EODEM units of information, LIDO 1.0 contains: Object Identifier, URI, Object Type, Materials, Measurements group, Title/Name group, Brief Description, Date group, Maker, Image, Credit Line, Lender Details, Export Date. [↩]
- Of the EODEM units of information, Spectrum XML 4.0 contains: Object Identifier, Materials, Measurements group, Title/Name group, Brief Description, Date group, Maker, Image, Credit Line, Value, Condition, Temperature group, Relative Humidity group, Lux Level group, UV Exposure group, Handling, Transport, Display, Security, Hazard. (The units in grey text are represented only by a free-text field, not granular data.) [↩]