
Written with Jeremy Ottevanger and delivered at Symbiosis of Tradition and Digital Technology (the CIDOC 2021 annual conference), online and Tallinn, 24 May 2022.
The National Gallery has a long tradition of producing detailed print catalogues of its collections. Despite the emergence of online methods of publication over the last 30 years, we have continued to focus on purely printed catalogues. But the work involved to produce a single print volume is immense; the public increasingly demands digital access; and our existing model of catalogue dissemination is no longer sustainable.
The Gallery is now embarking on a major programme which will increase the depth and richness of our online collection information by an order of magnitude, with digital versions of the existing print catalogues at its heart. Based on the findings of a pilot project which ran from 2019 to 2021, this paper explains the pipeline we have set up to turn our printed catalogues into digital files which can in turn be converted into multiple formats for digital dissemination, and from which individual sections can be extracted according to need. We will also explain how the pipeline, created for the retrospective conversion of existing volumes, is being adapted so that we can start publishing a few entries at a time online before they go to print, enabling us to take advantage of research as it happens. We will also touch upon the possibilities of enriching the texts by using natural language processing techniques to automate the identification and tagging of named entities within them.
Introduction
[Rupert] Our talk today, about the National Gallery’s recent work to put print catalogues online, falls into three parts: I’ll introduce the problem, and the solution, we adopted; and Jeremy Ottevanger, who worked on technical aspects, and I will talk about the solution in more detail as we discuss a series of projects which are leading up to the web publication of catalogue entries for the Gallery’s paintings.
Tradition: the problem
For those of you who don’t know us, I’d like to begin by introducing the National Gallery, on Trafalgar Square in London. We were founded in 1824, and are a national museum, holding the UK’s national collection of paintings in the western European tradition, dating from roughly 1250 to 1900. Because we were founded from scratch, we have very few objects in museum terms – only 2,393 paintings in our main collection.
But now I need to take you back to the Second World War, when – as is still happening today – culture and museums were threatened by bombs; and so the Gallery’s paintings were evacuated from London, ending up in a slate quarry in Manod, in north Wales.



Here, free from distractions, the Gallery’s staff – notably Martin Davies, the man on the far right in the picture immediately above – could give their undivided attention to the paintings.
The result was a series of catalogues, arranged by school of painting, the first of which was published immediately after the War in 1945.

These set a new standard in the detail and thoroughness of their assessments and descriptions. Work on the ‘schools catalogues’, as they were known, continued until 1971, and they eventually extended across the Gallery’s entire collection.
In the early 1990s, we decided that the schools catalogues were in need of a complete overhaul, and began work on a new series. The first of these was published in 1998; they became known as the ‘paintings series’.

With their large formats, lavish full-colour illustrations, extensive discussions, and detailed scientific and technical information, the paintings series again marked a significant step forwards in the publication of museum catalogue information. So far, eleven of these catalogues have been published, with another one in the press, covering about 850 paintings.
But these catalogues are also the problem: much of the Gallery’s knowledge is effectively contained in a highly traditional medium, printed books: if we think of the use of movable type, these go back in Asia to the 14th, and in Europe to the 15th, century. And our printed catalogues are large, expensive, and in many cases now out of print. In digital form, they mostly exist as QuarkXPress or, in a few more recent cases, as Adobe InDesign files, which are difficult to reuse.
We could use these to generate PDFs of individual entries – but they would be far from ideal, because they’d be laid out for print, not on-screen viewing. For example, we’d have to move readers around between many different sections, as much of what they need is contained in the front and back matter, not the individual catalogue entry – things like: information about how the catalogue is organised; abbreviations and glossary terms used in the entry; guidance on historic dates and measurements and how they’ve been treated; full references for any publications and exhibitions cited in the entry; and any appendices referred to in the entry. Whereas what we really want is to present readers with everything they’d need on a single page, without having to link out to read the next section or to consult a separate bibliography; and to give them a layout where images are close to the relevant content, not constrained by page layouts. And of course we want to take advantage of the opportunities that web-pages offer for hyperlinking, dynamic expansion of abbreviations, use of popups, etc.
So our problem is how to go from a static PDF laid out for print, to a dynamic, hyperlinked webpage laid out for on-screen use.
The solution: digital possibilities
Well, the answer is to use an interoperable intermediate format, marked up to characterise the text’s contents and to enable relationships between different parts of the text and other data sources. We decided to use the Text Encoding Initiative, or TEI, framework for XML, because it is long-established, stable, well-documented – and very, very rich. This lets us meet our editorial principles: as I’ve just explained, to provide a rich, practical experience for our readers, whilst also staying as close to the original texts and layouts as possible: we will correct obvious typos, but retain the original texts; but we also have the ability to add a curatorial update as a separate block of text; and, because we are presenting images online, we need to re-clear rights, which means updating the credit lines and moving them from the back matter into the individual captions.
Projects – 1: pilot
Clearly, doing all this wasn’t going to be simple, and we decided to start with a pilot project. The aim was to set up a production pipeline that starts with desktop publishing files and ends up with catalogue HTML and images being served to our website via our middleware – and to work out how long it would take to process the 700+ existing entries along the way. The pilot project ran from October 2019 to March 2021, and involved a range of people, from digitisation houses, picture researchers and proof-readers, through web developers and UX designers – and including Jeremy, developing the XSL templates needed for the project. We chose five paintings from amongst our list of 100 highlights, which covered catalogues published between 1998 and 2018:
- NG186: van Eyck, Portrait of Giovanni(?) Arnolfini and his Wife, from Campbell, The Fifteenth Century Netherlandish Paintings (1998)
- NG524: Turner, The Fighting Temeraire tugged to her last berth, from Egerton, The British Paintings (2000)
- NG583: Uccello, The Battle of San Romano, from Gordon, The Fifteenth Century Italian Paintings, 1 (2003)
- NG294: Veronese, The Family of Darius before Alexander, from Penny, The Sixteenth Century Italian Paintings, 2, Venice, 1540-1600 (2008)
- NG4077: Chardin, The Young Schoolmistress, from Wine, The Eighteenth Century French Paintings (2018)
One point I’d like to emphasise is that, for various reasons, ours is a very low-tech solution to the problem of generating HTML catalogue texts. Other pipelines exist, but they rely upon implementing a quite complicated technology stack before being able to generate the files. After the initial file conversion to XML, which was outsourced, we simply used two free tools: an XML-enabled text editor to mark up the texts, and a free XSLT processor. (Use of a spreadsheet (paid for or free) to ease the generation of command-line transform commands is optional.) These are enough to generate web-ready HTML files. We only use complex software when it comes to publishing our web pages: 0ur CIIM middleware for integrating the catalogue pages with our other collection data, and our web CMS, Umbraco. (I should add that, for production, we are using the fully-featured Oxygen XML editor – but it’s not necessary.)
Publication pipeline
This is the work-flow that evolved:
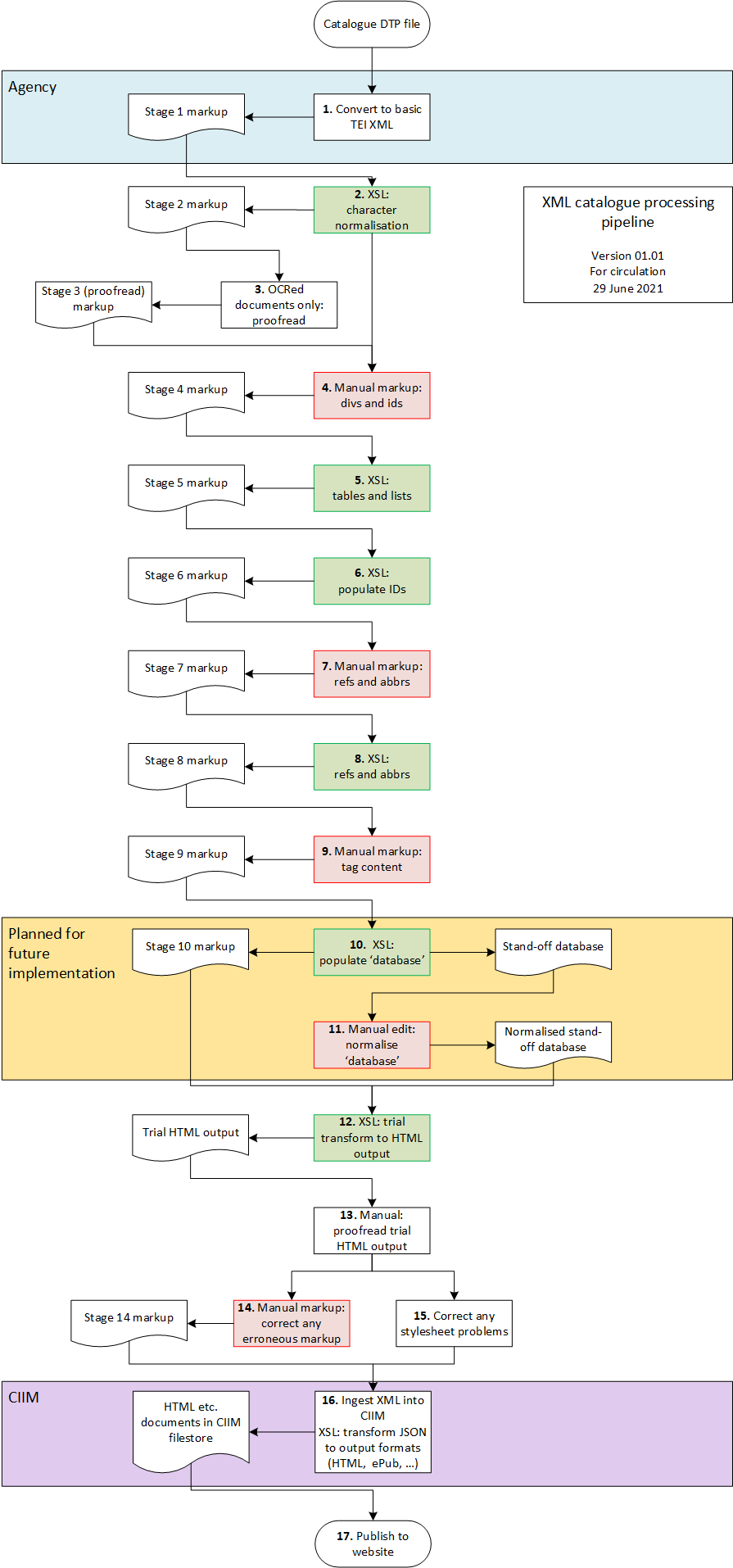
It starts with conversion of the text to XML, and some basic normalisations (stages 1-2). If a text has been OCRed, it’s proofread (3). There are a series of iterative steps applying automated and manual mark-up, centred around structuring, correcting variable mark-up in the originated files, and adding the identifiers and references needed to make the web-pages work, as well as marking up content: glossaries, abbreviations, and converting formatting tags so that they identify the particular kind of content being highlit (4-9). (We had hoped to extract data into a central ‘database’ file which could be used to repopulate entries from a central, standardised source, but time and money ran out (10-11).) Once mark-up is completed, we generate trial HTML pages, and the whole thing is proofread to make sure nothing’s been garbled, and everything is where it should be (12-13); any changes required are made to the mark-up – and the XSL templates, if the stylesheets have failed to take some new peculiarity of the text into account (14-15). Then the XML and accompanying images are ingested into the CIIM, converted to HTML, and delivered to Umbraco, which publishes them to the website (16-17).
XSL development
[Jeremy] The XSL transformations had several overall objectives: to take XML representing semi-structured text that is ready to be reorganised in many different ways, including references to (and from) external resources; and to use it to deliver a series of concrete outputs: rich TEI-XML files, from which we can generate one HTML file for each painting and artist, that also includes contextualising content plus only and all of the footnotes, abbreviations, bibliographic references, lists of historic exhibitions and appendices that pertain to that entry; and similar ePub publications.
Rupert has already touched on the staged approach to processing, including six XSLT-driven stages – plus a seventh recently added for born-digital catalogues, and stylesheets we can run for quality control, to check for elements that lack attributes and so on, helping with the manual mark-up tasks.
Each stage in fact includes multiple transformations, and is generally followed by human intervention in the form of proof-reading and/or manual markup. The final transformation into HTML, as Rupert will explain, should be mistake-free, so it can be published on the web without further intervention.
The stages were necessary precisely because certain automated steps couldn’t proceed without manual interventions, such as to add some key structure and IDs, or to insert and tags into plain text. But it is also helpful to break the many operations into separate transformations. This lets us check the outputs of each process and also debug more easily; and it simplifies things when one step depends on the completion of another. In theory this could sometimes be done within one stylesheet, but it can be extremely complex. As I’ll explain, we had to do this with the HTML generation and it’s both exhilarating and mind-bending!
For instance Stage 6 includes separate stylesheets for each attribute of type, n and xml:id, and another that merges in an external XML file with corrected image file names; and in stage 8 a series of transforms use these various attributes to start to build links between references and targets, and to expand abbreviations.
I’d never worked on an XSLT challenge as large as this, and various challenges kept recurring so that eventually I started to recognise where a solution would be appropriate.

The HTML document we generate represents a core of data together with a whole collection of other elements assembled from elsewhere. A templating language like XSL, meanwhile, works most easily when applied to a set of elements of known form, and you can’t really create part of the output and later on in the process go back in to fill in some gaps. We decided to do a lot of the assembly logic first to generate a “virtual XML document” in an XSL variable, which would then contain all and only the elements that would be needed in the final output (or almost all). This virtual document is then passed to lots of other templates to generate HTML. It works well, but debugging is complicated …
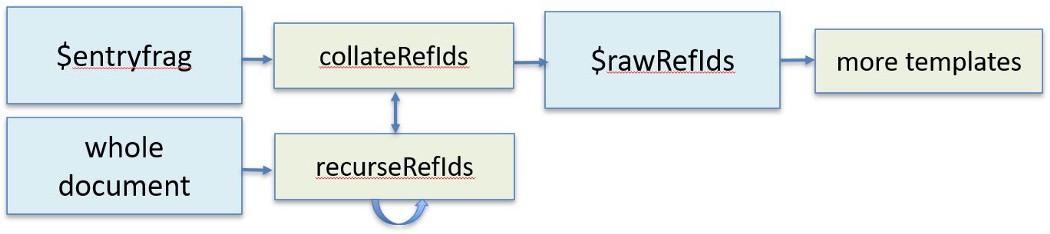
A templating language is also not well adapted to recursion, which is trivial in many programming contexts. To create the HTML, each painting entry requires a bibliography and lists of exhibitions, abbreviations and glossary terms that only contain relevant items which may be referred to directly within the entry or by things that the entry refers to – and beyond. So here, the chain looks like this:
- collateRefIds looks at all references in the virtual document we just made and passes them to “recurseRefIds”.
- This looks in the whole document for the things that were referenced, and checks if they themselves refer to anything,
- If they do it then recurses to do the same again, up to five times.
- It passes the results back to collateRefIds.
- The result is another variable holding a list of all the IDs of referenced items that pertain to the compiled entry, wherever they are in the original document. They can then be sorted, deduplicated and used as the basis for making HTML lists.
Online delivery
[Rupert] So, we have a process that takes richly-marked up XML files and uses them to generate HTML pages; but how do we incorporate these into our website publication pipeline?
We are increasingly using middleware to aggregate collections-related data from multiple sources and present it via a single endpoint; we use the CIIM, and so we commissioned its suppliers, Knowledge Integration, to configure it to:
- Take the finished XML file, accompanying image files, and XML-to-HTML XSL template;
- Generate the HTML files, transforming any internal hyperlinks to links to other files or CIIM entities,
- and add them to the CIIM’s file store, along with copies of the accompanying image files and the source files;
- If necessary, create a ‘primary’ record for the individual catalogue entry, and link it to the CIIM records for the relevant publication and painting;
- Create a ‘version’ sub-record for the particular version of the entry being extracted;
- Assign a Persistent Identifier, PID, [link] to the newly-generated HTML file;
- Ensure that one additional PID, for the current version of an entry, is attached to the latest HTML file
- (This is important because, as an academic resource, researchers will need to be able to cite a particular version of any given entry);
- And write a copy of the relevant files representing this version to the CIIM’s backup vault.
- The CIIM is then queried by our Umbraco content management system, and the relevant files and metadata are retrieved and cached in Umbraco for delivery to the Gallery’s website.
Findings
Over the course of the project, we spent about 51 days on text mark-up, including the use of automated tagging wherever possible. Our 5 entries totalled 115,000 words, so it equates to marking up about 2,250 words in a day. This means that marking up all our paintings series catalogues would take 2,016 working days, at a slightly revised estimated rate of 2,650 words per day; but then, we’re dealing with about 5.3 million words. This is not trivial – but it is doable; and, at just over 9 years, compares favourably with the 24 years that would be required to put these 12 catalogues through the press.
Projects – 2: Raphael pilot (born-digital)
But the initial pilot project has also helped us to identify what we need to do to publish catalogue entries digitally before they go to print. This would mean that we could release single entries or small groups quickly, without having to assemble a huge print volume of 60 or 70 entries before publication, which makes writing catalogue entries a much more attractive proposition, and lets us incorporate their creation into other projects, such as exhibitions.
So we’re piloting a revised pipeline for born-digital catalogues with entries for our 10 Raphaels. These were originally going to be published in time for our delayed quincentenary Raphael exhibition, which actually opened on 9 April this year; but delays to the writing and a time-consuming CIIM upgrade mean that our aim is now to get at least one entry online before the exhibition closes on 31 July.
As part of this, we’ve reviewed our pipeline and XSL templates so that we can pass entries through the mark-up pipeline one at a time, rather than work on a whole catalogue at once; refine the versioning in the CIIM, so that unchanged entries aren’t reversioned when a catalogue file is parsed for newly-completed entries; and add richer version information and pre-formatted citations for the entry into our XSL templates.
Projects – 3: ‘200 for 200’ (Digital Dossiers)
The Gallery is also planning a major programme of projects in time for its Bicentenary Year, running from May 2024 to May 2025. Some of these fall under the umbrella of our Digital Dossiers Programme, which aims to start making ‘everything we know about our paintings available in one place’. As part of this, we will use our cataloguing pipeline to digitise 200 entries in time for the Bicentenary. The bulk of these will come from the paintings series of catalogues, which means that we will digitise about 20% of it.
We’ll also use this opportunity to make some further refinements to the pipeline: notably creating a ‘database file’ of cited elements – bibliographic references, exhibitions, etc. – that are formatted consistently, and that can be reused across multiple existing and new catalogues. We’ll also improve the CIIM’s handling of the HTML files so that it removes links to as-yet-unpublished entities; and, later, add the ability to include links to external identities, based upon automated tagging.
This tagging will be carried our during a Collaborative Doctoral Project that we’ve set up with the GATE team at the University of Sheffield, on ‘Natural Language Processing for Art-Historical Information Extraction’. An initial stage will investigate the creation of a highly-tuned pipeline for Named Entity Recognition and Entity Linking for art-historical texts; it will go on to use the catalogue texts as one source from which to automatically extract meaningful data from provenances, technical descriptions, etc.
We also hope to extend our Raphael pilot into a major, ongoing programme of digital-first cataloguing.
Conclusions
As I mentioned above, for various reasons, our digital catalogues have not yet been published on the Gallery’s live website; but we hope that they will be available within a couple of months, via https://www.nationalgallery.org.uk/research/research-resources/national-gallery-catalogues.
But to conclude briefly, I hope we’ve shown you how, in transposing our print-first cataloguing culture into a digital-first one, we have established a symbiotic relationship between the National Gallery’s traditional way of publishing catalogues, and digital technology.
Further reading
My co-author, Jeremy Ottevanger, has also published a couple of posts relating to his work on these projects on his Sesamoidish blog: Catalogues to TEI to HTML at the National Gallery and Climbing Mount Indigestible.