
Alongside the 200 online catalogue entries in 200 Paintings for 200 Years, and the bibliographies and exhibition histories I wrote about recently, the National Gallery has now put on its website a provenance for every painting in the main collection. This post talks in brief about why provenances are important, and what makes them difficult to deal with, before outlining what we’ve done at the Gallery.
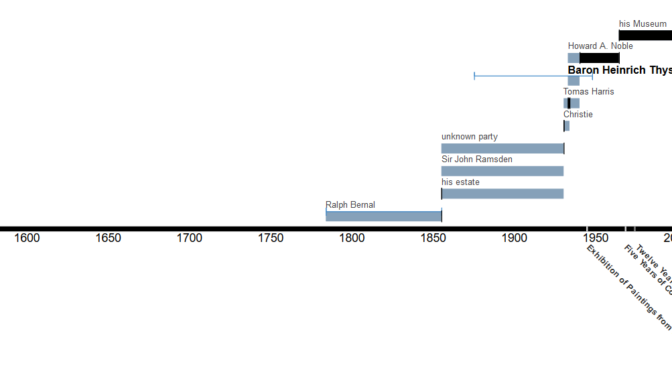
A note of caution: the image above is misleading. We haven’t published provenances as structured data, let alone visualisations. It’s taken from an old screengrab of Carnegie Museum of Art’s Elysa provenance-parsing tool, and I used it because it provides a visual representation of a provenance.
Continue reading News from the National Gallery – 3